What to do if I’ve been doxed: Actions to take in the first 24hours.
If you are in immediate danger, please call your local emergency number.
This is a step-by-step guide on actions to consider after being targeted online. It’s direct and concise by design. There’s no “right way” or order to go about things. Here is information so you can come up with an action plan that best supports your incident, goals, and needs.
Trigger warning: For someone not in immediate need of an action plan, this guide could be triggering. If you are concerned about being targeted, scroll below for prevention-focused guides.
Audience: Have you been doxed (doxxed)? And you are concerned?
Personal information — that you consider to be private and sensitive — has been published online. Information can include (but not limited to) your phone number, home address, email address, employer info, family members’ personal info, photos including intimate images, or driver’s license or SSN.
And you interpret this dox to be an explicit or implicit threat. You experience the publication of this info as some attempt to stalk, intimidate, silence, retaliate, or extort.
Before we begin:
No matter what, please consider these 3 things throughout the next 24 hrs:
[1] Save everything; (try to) delete nothing.
Take screenshots. Make sure the date and URL is in there. If not, try to save that. All evidence helps. Even if evidence includes content you may regret writing yourself, save it.
If you must delete, take a screenshot first. Deleting might impact your ability later if you need to take legal actions.
[2] Your safety is the #1 priority.
Remember to breathe, to think clearly.
Whatever negative stories you have, please know, this isn’t your fault.
[3] Tell someone you trust.
You aren’t alone. People will step up to help. Even highly functioning and capable people can use help in these situations. You deserve it. And this way, there’s somewhat of a witness.
In the 1st hour:
Are you in a safe place?
If you feel you are in a location that is unsafe or compromised, call 911. Tell someone you trust (ideally via encrypted communication — Whatsapp, Signal). Move your location to somewhere you consider safe. Make sure your cellphone has geo-location turned off.
Can you think clearly?
Once you are in a safe place, can you think clearly? You may be in fight or flight mode. This is just your body and brain reacting. Take a 3 deep, long breaths. Try to de-escalate, so you can figure out what to do next.
Let’s triage and stop the “bleeding.”
Report the dox to the platform where your info appears. Keywords: “report violations” to terms of service or community guidelines. While filling a form out once, save that for the future (so you don’t have to repeat yourself). This is the first step to stop the spread of your personal info.
Has a physical, credible threat been made against you? Call the police or FBI. If you can, go with a friend. Make sure you ask for a copy and write down your case number.
Has an online account been compromised? Change your passwords — starting with the compromised account. Don’t forget to jot it down — pen and paper — or in your password saver. Add 2FA. Add higher privacy settings for your phone, email, or social media accounts.
Next hours:
What are you most concerned about?
Take out a piece of paper and identify what you are most concerned about. This will help you determine your goals and action steps.
What are you trying to protect? What “assets”?
Could be email, location, files, reputation, physical safety, safety of someone you know, real name, etc.
What part or area of life?
Who else could it impact?
Who do you think you are protecting it from?
Are you able to tell someone what happened?
Documenting specific details of what’s going on is one of the most valuable things you can do in the moment. You may have to share this story over again, so documenting now will make it easier. You may be asked — “who do you think is behind this? why do you think you are being targeted?” If you have an idea, definitely save this info. The question might feel invalidating, but provides important context for those trying to help you.
How will you monitor what’s going on?
Create a way to monitor what’s going on, so you can assess any risks. Set a Google alert for your name or any keywords. Add a filter in your gmail. Ask a friend to monitor your accounts and email you.
Truth About Cloud Storage: When many of us upload a file to the cloud, we tend to think it will be there forever, ready to be downloaded and accessed on command, or at least when you have a good internet connection.
But the truth about the cloud is that it’s actually just a bunch of other hard drives, and your files are really only accessible as long as your provider stays in business and the data formats in which your files are saved are still used by existing software. In addition, keeping all those files at your fingertips takes a lot more thought and effort than you may have considered.
Sure, all digital files are just bits and bytes differentiated by how they’re organized, but the reality isn’t quite that simple. For example, a basic text file has an extension indicating it’s a text file and is read using either the ACSII or Unicode standard that allows the bits 01101000 01101001 to be read as “hi.” Similar rules apply to more complex file formats. That all works great, right up until the format falls out of favor, the software is abandoned or both.
After all, when was the last time you played a song using RAM or WMA formats? How many .mov or .wmv files do you download to watch videos? With technology moving away from proprietary media formats like Real Media, Windows Media and QuickTime to shared standards like MPEG-4 and MP3, software to play back those file types is either obsolete or doomed to obsolescence. Even current formats aren’t safe. Fraunhofer IIS, the foundation responsible for giving us the MP3 format, stepped away from the currently ubiquitous file type for music and has advocated for the adoption of formats like AAC and FLAC.
The Future for Your Outdated Files
Clearly, we’ll need to preserve the ability to read or automatically convert outdated formats to maintain continuity of access as more people rely on cloud storage and backup, adding decades’ worth of data to hard drives on servers in sprawling data centers. Online converters will likely tackle this job, although what that really means is that users will upload a file to a server, the server will do the complicated job of reformatting the structure of the bits and bytes in that file, add a new extension, and allow the users to download the result in the desired format when they need this data.
Look for this to become more common with newer generations of formats slowly but surely being adopted by large enough software ecosystems. After more than a decade of popular, widespread cloud storage and petabytes of data uploaded by hundreds of millions of people, we’re certainly due for some of those files’ formats to become obsolete.
Can I Have My Data Now?
So how do all those petabytes of data we’re uploading to cloud providers stay secure and accessible? After all, computers age, and servers crash, die and get replaced. How do data centers deal with both routine and catastrophic problems while maintaining the 99.9 percent uptime they promise to users?
Well, the answer is more servers, specifically failover servers that shadow their active counterparts through periodic scheduled synchronization and come online when necessary. But sometimes, even these backups aren’t enough, and data centers turn to magnetic tape. Yes, far from being a relic of early computing history, magnetic tapes are not only alive and well as a storage medium, they’re thriving. And while it may seem weird that your movie shot on the latest smartphone with 4K quality will probably end up residing in a storage locker, backed up on a technology you probably thought was only used in dusty government offices and exhibited in museums, that’s the strange reality.
Ultimately, cloud storage is about having your files accessible no matter what happens or what device you use. Magnetic tapes can be encrypted and keep your files safe for 30 years without any deterioration or artifacts whereas hard drives of servers can fail in as little as five years. The reason why magnetic tapes went out of style is because loading them and reading data from them is a hassle. It’s a slow, complicated process compared to the incredible speed of modern solid state hard drives. But if they’re only used to store files in the event of enough failover servers dying, or for legal compliance reasons, they make a perfectly viable alternative to external hard drives, which also tend to fail in roughly five years.
So, the bottom line here is that cloud storage providers’ ease of use and ubiquity hides a complicated and less than glamorous system for storing your data on countless hard drives and magnetic tapes, merely presenting you with an easy to use drag-and-drop façade. That said, the result has proven to be extremely useful, and the data centers involved are run by experts who understand the challenges involved and have been consistently rising to meet them. So as long as your provider is still in business, chances are that your data is safe and easily accessible, backed up on dozens of servers. And maybe even a magnetic tape or two in a climate-controlled basement.
How Search Engines Work: The good news about the Internet and its most visible component, the World Wide Web, is that there are hundreds of millions of pages available, waiting to present information on an amazing variety of topics. The bad news about the Internet is that there are hundreds of millions of pages available, most of them titled according to the whim of their author, almost all of them sitting on servers with cryptic names. When you need to know about a particular subject, how do you know which pages to read? If you’re like most people, you visit an Internet search engine.
How Search Engines Works
Internet search engines are special sites on the Web that are designed to help people find information stored on other sites. There are differences in the ways various search engines work, but they all perform three basic tasks:
They search the Internet — or select pieces of the Internet — based on important words.
They keep an index of the words they find, and where they find them.
They allow users to look for words or combinations of words found in that index.
Early search engines held an index of a few hundred thousand pages and documents, and received maybe one or two thousand inquiries each day. Today, a top search engine will index hundreds of millions of pages, and respond to tens of millions of queries per day. In this article, we’ll tell you how these major tasks are performed, and how Internet search engines put the pieces together in order to let you find the information you need on the Web.
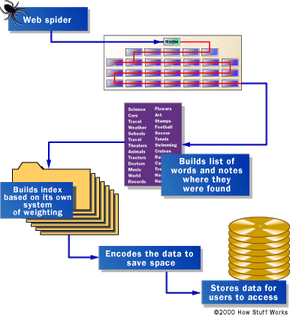
Web Crawling
“Spiders” take a Web page’s content and create key search words that enable online users to find pages they’re looking for.
When most people talk about Internet search engines, they really mean World Wide Web search engines. Before the Web became the most visible part of the Internet, there were already search engines in place to help people find information on the Net. Programs with names like “gopher” and “Archie” kept indexes of files stored on servers connected to the Internet, and dramatically reduced the amount of time required to find programs and documents. In the late 1980s, getting serious value from the Internet meant knowing how to use gopher, Archie, Veronica and the rest.
Today, most Internet users limit their searches to the Web, so we’ll limit this article to search engines that focus on the contents of Web pages.
Before a search engine can tell you where a file or document is, it must be found. To find information on the hundreds of millions of Web pages that exist, a search engine employs special software robots, called spiders, to build lists of the words found on Web sites. When a spider is building its lists, the process is called Web crawling. (There are some disadvantages to calling part of the Internet the World Wide Web — a large set of arachnid-centric names for tools is one of them.) In order to build and maintain a useful list of words, a search engine’s spiders have to look at a lot of pages.
How does any spider start its travels over the Web? The usual starting points are lists of heavily used servers and very popular pages. The spider will begin with a popular site, indexing the words on its pages and following every link found within the site. In this way, the spidering system quickly begins to travel, spreading out across the most widely used portions of the Web.
Google began as an academic search engine. In the paper that describes how the system was built, Sergey Brin and Lawrence Page give an example of how quickly their spiders can work. They built their initial system to use multiple spiders, usually three at one time. Each spider could keep about 300 connections to Web pages open at a time. At its peak performance, using four spiders, their system could crawl over 100 pages per second, generating around 600 kilobytes of data each second.
Keeping everything running quickly meant building a system to feed necessary information to the spiders. The early Google system had a server dedicated to providing URLs to the spiders. Rather than depending on an Internet service provider for the domain name server (DNS) that translates a server’s name into an address, Google had its own DNS, in order to keep delays to a minimum.
When the Google spider looked at an HTML page, it took note of two things:
The words within the page
Where the words were found
Words occurring in the title, subtitles, meta tags and other positions of relative importance were noted for special consideration during a subsequent user search. The Google spider was built to index every significant word on a page, leaving out the articles “a,” “an” and “the.” Other spiders take different approaches.
These different approaches usually attempt to make the spider operate faster, allow users to search more efficiently, or both. For example, some spiders will keep track of the words in the title, sub-headings and links, along with the 100 most frequently used words on the page and each word in the first 20 lines of text. Lycos is said to use this approach to spidering the Web.
Other systems, such as AltaVista, go in the other direction, indexing every single word on a page, including “a,” “an,” “the” and other “insignificant” words. The push to completeness in this approach is matched by other systems in the attention given to the unseen portion of the Web page, the meta tags. Learn more about meta tags on the next page.
Meta Tags
Meta tags allow the owner of a page to specify key words and concepts under which the page will be indexed. This can be helpful, especially in cases in which the words on the page might have double or triple meanings — the meta tags can guide the search engine in choosing which of the several possible meanings for these words is correct. There is, however, a danger in over-reliance on meta tags, because a careless or unscrupulous page owner might add meta tags that fit very popular topics but have nothing to do with the actual contents of the page. To protect against this, spiders will correlate meta tags with page content, rejecting the meta tags that don’t match the words on the page.
All of this assumes that the owner of a page actually wants it to be included in the results of a search engine’s activities. Many times, the page’s owner doesn’t want it showing up on a major search engine, or doesn’t want the activity of a spider accessing the page. Consider, for example, a game that builds new, active pages each time sections of the page are displayed or new links are followed. If a Web spider accesses one of these pages, and begins following all of the links for new pages, the game could mistake the activity for a high-speed human player and spin out of control. To avoid situations like this, the robot exclusion protocol was developed. This protocol, implemented in the meta-tag section at the beginning of a Web page, tells a spider to leave the page alone — to neither index the words on the page nor try to follow its links.
Building the Index
Once the spiders have completed the task of finding information on Web pages (and we should note that this is a task that is never actually completed — the constantly changing nature of the Web means that the spiders are always crawling), the search engine must store the information in a way that makes it useful. There are two key components involved in making the gathered data accessible to users:
The information stored with the data
The method by which the information is indexed
In the simplest case, a search engine could just store the word and the URL where it was found. In reality, this would make for an engine of limited use, since there would be no way of telling whether the word was used in an important or a trivial way on the page, whether the word was used once or many times or whether the page contained links to other pages containing the word. In other words, there would be no way of building the ranking list that tries to present the most useful pages at the top of the list of search results.
To make for more useful results, most search engines store more than just the word and URL. An engine might store the number of times that the word appears on a page. The engine might assign a weight to each entry, with increasing values assigned to words as they appear near the top of the document, in sub-headings, in links, in the meta tags or in the title of the page. Each commercial search engine has a different formula for assigning weight to the words in its index. This is one of the reasons that a search for the same word on different search engines will produce different lists, with the pages presented in different orders.
Regardless of the precise combination of additional pieces of information stored by a search engine, the data will be encoded to save storage space. For example, the original Google paper describes using 2 bytes, of 8 bits each, to store information on weighting — whether the word was capitalized, its font size, position, and other information to help in ranking the hit. Each factor might take up 2 or 3 bits within the 2-byte grouping (8 bits = 1 byte). As a result, a great deal of information can be stored in a very compact form. After the information is compacted, it’s ready for indexing.
An index has a single purpose: It allows information to be found as quickly as possible. There are quite a few ways for an index to be built, but one of the most effective ways is to build a hash table. In hashing, a formula is applied to attach a numerical value to each word. The formula is designed to evenly distribute the entries across a predetermined number of divisions. This numerical distribution is different from the distribution of words across the alphabet, and that is the key to a hash table’s effectiveness.
In English, there are some letters that begin many words, while others begin fewer. You’ll find, for example, that the “M” section of the dictionary is much thicker than the “X” section. This inequity means that finding a word beginning with a very “popular” letter could take much longer than finding a word that begins with a less popular one. Hashing evens out the difference, and reduces the average time it takes to find an entry. It also separates the index from the actual entry. The hash table contains the hashed number along with a pointer to the actual data, which can be sorted in whichever way allows it to be stored most efficiently. The combination of efficient indexing and effective storage makes it possible to get results quickly, even when the user creates a complicated search.
Building a Search
Searching through an index involves a user building a query and submitting it through the search engine. The query can be quite simple, a single word at minimum. Building a more complex query requires the use of Boolean operators that allow you to refine and extend the terms of the search.
The Boolean operators most often seen are:
AND – All the terms joined by “AND” must appear in the pages or documents. Some search engines substitute the operator “+” for the word AND.
OR – At least one of the terms joined by “OR” must appear in the pages or documents.
NOT – The term or terms following “NOT” must not appear in the pages or documents. Some search engines substitute the operator “-” for the word NOT.
FOLLOWED BY – One of the terms must be directly followed by the other.
NEAR – One of the terms must be within a specified number of words of the other.
Quotation Marks – The words between the quotation marks are treated as a phrase, and that phrase must be found within the document or file.
Future Search
The searches defined by Boolean operators are literal searches — the engine looks for the words or phrases exactly as they are entered. This can be a problem when the entered words have multiple meanings. “Bed,” for example, can be a place to sleep, a place where flowers are planted, the storage space of a truck or a place where fish lay their eggs. If you’re interested in only one of these meanings, you might not want to see pages featuring all of the others. You can build a literal search that tries to eliminate unwanted meanings, but it’s nice if the search engine itself can help out.
One of the areas of search engine research is concept-based searching. Some of this research involves using statistical analysis on pages containing the words or phrases you search for, in order to find other pages you might be interested in. Obviously, the information stored about each page is greater for a concept-based search engine, and far more processing is required for each search. Still, many groups are working to improve both results and performance of this type of search engine. Others have moved on to another area of research, called natural-language queries.
The idea behind natural-language queries is that you can type a question in the same way you would ask it to a human sitting beside you — no need to keep track of Boolean operators or complex query structures. The most popular natural language query site today is AskJeeves.com, which parses the query for keywords that it then applies to the index of sites it has built. It only works with simple queries; but competition is heavy to develop a natural-language query engine that can accept a query of great complexity.
What Is Privilege Escalation Attack: Privilege escalation is a vulnerability used to gain access to applications, networks, and mission-critical systems. And privilege escalation attacks exploit security vulnerabilities and progressively increase criminal access to computer systems. These attacks are classified into vertical and horizontal privilege escalation based on the attack’s objective and strategy. There are several types of privilege escalation attacks, and each of them exploits a unique set of vulnerabilities having its own set of technical requirements.
In this article, we’ll discuss privilege escalation attack in-depth, how it works, the types and impact of these attacks, and how to prevent privilege escalation attacks. Let’s get started.
What Is Privilege Escalation Attack?
Privilege escalation is a common method attackers use to gain unauthorized access to systems and networks within a security perimeter. It’s an attack vector faced by many organizations due to a loss of focus on permissions. As a result, existing security controls within organizations are often insufficient to prevent attacks. Attackers initiate privilege escalation attacks by detecting the weak points in an organization’s IT infrastructure.
Privilege escalation attacks take place when a malicious actor gains access to a user account, bypasses the authorization channel, and successfully access sensitive data. The attacker can use obtained privileges to execute administrative commands, steal confidential data, and cause serious damage to server applications, operation systems, and the company’s reputation. While deploying these attacks, attackers are generally attempting to disrupt business function by exfiltrating data and creating backdoors.
How Do Privilege Escalation Attacks Work?
Privilege escalation attacks represent the layer of a cyberattack chain where criminals take advantage of a vulnerable system to access data from an unauthorized source. However, there are various vulnerable points within a system, but some common entry points include Application Programming Interfaces and Web Application Servers. Attackers authenticate themselves to the system by obtaining credentials or bypassing user accounts to initiate the attack. Apart from it, attackers find different loopholes in account authorization access to sensitive data.
Regrading how a privilege escalation attack works, attackers usually use one of these five methods, including credential exploitation, system vulnerabilities, and exploits, social engineering, malware, or system misconfigurations. By implementing one of these techniques, malicious actors can gain an entry point into a system. Depending on their goals, they can continue to uplift their privileges for taking control of a root or administrative account.
Common Privilege Escalation Attacks Examples
Here are some common examples of real-world privilege escalation attacks.
Windows Sticky Keys: It’s one of the most common examples of privilege escalation attacks for Windows operating systems. This attack requires physical access to the targeted system and the ability to boot from a repair disk.
Windows system internals: commands provide a source of privilege escalation attacks in Windows. This method assumes that the attacker has a backdoor from a previous attack, such as Windows sticky keys method. The attacker must have access to local administrative rights and then logs into backdoor accounts to escalate permissions to the system level.
Android and Metasploit: Metasploit is a well-known tool, including a library of known exploits. This library contains the privilege escalation attack against rooted android devices. It creates an executable file, known as superuser binary, which allows attackers to run commands with administrative or root access.
Privilege Escalation Attacks & Techniques
The goal of the privilege escalation attack is to get high-level privileges and find entry points to critical systems. There are various techniques attackers use for privilege escalation. Here are three of the most common ones.
Bypass user account control: The user account control serves as a bridge between users and administrators. It restricts application software to standard permissions until an admin authorizes privilege increase.
Manipulating access tokens: In this case, the attacker’s main task is to trap the system into believing that the running processes belong to another user other than the authorized user that started the process.
Using valid accounts: Criminals can leverage credential access techniques to get credentials of certain user accounts or streal them using social engineering. Once attackers access the organization’s network, they can use these credentials to bypass access control on IT systems and various resources.
What Are The Types Of Privilege Escalation Attacks?
There are two types of privilege escalation attacks. These include.
1. Horizontal Privilege Escalation
It’s a type of attack in which attackers expand their privileges by taking control of another account and misusing the authorized privileges granted to the legitimate user. Phishing campaigns are used to gain access to user accounts. For elevating the permissions, attackers either exploit vulnerabilities in the OS to gain root-level access or leverage hacking tools, such as Metasploit.
2. Vertical Privilege Escalation
This type of attack occurs when a criminal gains direct access to an account with the intent to perform similar actions as the legit user. Vertical privilege attack is easier to perform as there is no desire to elevate permissions. In this scenario, the attack focuses on account identification with necessary privileges and gaining access to that account.
Impact Of Privilege Escalation Attack
Privilege escalation attacks can impact in the following ways.
It can enter the organization’s IT infrastructure
Modify permissions to steal sensitive information
Add, delete or modify users
Create backdoor for future attacks
Gain access systems and files and disrupt the operations
Crash the website
How To Prevent Privilege Escalation Attacks?
Here are some best practices to prevent privilege escalation attacks.
Protect and scan your systems, network, and application. You can use effective vulnerability scanning tools to detect insecure and unpatched operating systems, applications, weak passwords, misconfigurations, and other vulnerabilities.
It’s essential to manage privileged accounts and ensure their security. The security team needs an inventory of all accounts where they exist and their purpose.
Establish and enforce robust policies to ensure that users and strong and unique passwords. Use multi-factor authentication to add an extra security layer while overcoming vulnerabilities arising due to weak passwords.
Users are the weakest link in the security chain, putting the entire organization at risk. Businesses should implement robust security awareness programs with effective training.
Secure databases and sanitize user inputs. Databases are attractive targets of criminals as web applications store all their data in databases, such as login credentials, configuration settings, and user data. With one successful attack, such as SQL injection, criminals can access all sensitive information and leverage it for further attacks.
What is Remote code execution: Cybercriminals use a wide range of techniques to target vulnerable systems, and remote code execution is one of them. According to a 2020 Global Threat Intelligence Report by NTT, remote code execution is the most used attack strategy, followed by injection attacks. The major benefit of this technique to hackers is that they can attack your system from anywhere, regardless of the location.
A remote code execution facilitates an arm’s length attack allowing criminals to get away unharmed while leaving your data, business, and operations suffer irreparable damage. In this article, we will learn about remote code execution vulnerability, how it works, and what you should do to prevent this vulnerability.
What Is Remote Code Execution (RCE)?
A remote code execution or RCE is one of the most critical attacks that can be executed on an application or a server. It refers to the ability of an attacker to access and modify a system without authority and regardless of the location. RCE enables an attacker to take over a server or a system by running arbitrary malicious software.
RCE is a vulnerability that can be exploited by creating malicious code and injecting it into the server using an input. The server executes the command unknowingly, and it allows criminals to gain access to the system. The attacker might try to escalate privileges after gaining access. It can lead to a full compromise of the vulnerable web server or application.
How Does Remote Code Execution Vulnerability Work?
In a remote code execution attack, an intruder intentionally exploits an RCE vulnerability to execute malware. It can be done using a form, query components, cookies, or uploading files to an application. While developing an application or a website, many developers overlook the need for input data validation and leave their applications vulnerable.
This kind of vulnerability is widely used to execute malicious code remotely. Here are the general steps an attacker uses to exploit an RCE vulnerability.
RCE
Cybercriminals scan machines, applications, or websites over the Internet for known vulnerabilities that can open the door to an attack.
Once they find a suitable vulnerability, they exploit it for entry and access.
Then they execute malicious code on the system to unleash the typical havoc such as stealing information, altering permissions, encrypting or destroying files, and downloading malware, based on the state of the compromised machine, vulnerabilities found, and tools available to criminals.
The malicious code execution is generally achieved using terminal commands and bash scripts. The attacker injects the code into a vulnerable application that executes it or calls the kernel to execute it.
Example Of An RCE Attack
Remote Code Execution attacks are so pervasive, commonplace, and widespread that it’s difficult to choose amongst the countless examples. Let’s see one of the biggest and devastating examples of an RCE attack.
On May 12, 2017, it was revealed that hundreds of thousands of systems worldwide were infected by WannaCry. It’s a malware that encrypts computer files, locks out the users, and demands a ransom payment to unlock or decrypt files. WannaCry malware allows remote code execution if a hacker sends a specially crafted message to Microsoft Server Message Block (SMB). It’s a protocol used to share access to files, printers, and other resources on a network.
The hacker scans the Internet to find vulnerable ports and uses one of the alleged U.S National Security Agency tools called “EternalBlue”. Once the SMB vulnerability is confirmed, the hacker uses another NSA tool called DoublePulsar to install WannaCry ransomware on the compromised system.
Impact Of Remote Code Execution Exploit
Remote code execution can leave a system, application, and user at high risk, resulting in an impact on the integrity and confidentiality of the data. A hacker who can execute commands with server or system privileges can
Change access privileges
Add, read, delete or modify data and files
Turn on and off configurations and modify services
Communicate to the servers
How To Prevent Remote Code Execution Vulnerability?
To survive in this ever-evolving threat landscape, it’s necessary to have robust security measures in place. You can prevent remote code execution vulnerability by using the following techniques.
It may not be possible to always prevent an RCE attack, but early alert systems can help you take preventive measures. Using a monitoring system can help you detect behaviors that can lead to a compromised system or server.
Use firewalls and other security tools that can prevent common automated attacks. Deploy and run vulnerability scanning tools and penetration testing to fix the vulnerabilities ahead of an attack.
Always keep your operating systems, software, and third-party tools up to date. Timely patching or installation of software updates ranks as the best security measure in preventing RCE attacks.
Always treat the interaction field as unreliable since the developer has no control over the user-entered data.
Limit access to the interpreter and ensure that users have only those privileges required to perform a task when setting up the server for the application.
Always use safe practices to upload files and never let users decide the extension or content of the files on the webserver.
How To Fix the ACE Vulnerability In Adobe After Effects:Adobe uncovered a new arbitrary code execution vulnerability (ACE) in Adobe After Effects. The flaw, which is tracked as CVE-2022-23200, has a base score of 7.8 out of 10.0 in the CVSS scoring system. The successful exploitation of this vulnerability may lead to arbitrary code execution in the context of the current user.
Since it is a high severity vulnerability with code execution permissions, it is good to fix the flaw before join the list of victims. Let’s see how to Fix the new ACE vulnerability in Adobe After Effects (AE).
What Is Adobe After Effects?
After Effects (AE) is a popular photo and video editing program developed by Adobe. It gains high tractions because of its professional toolset. Its toolset allows editors to complete any kind of creative editing work from basic editing to character animation, object removal from video clips, 3D designs, and more. It is a subscription-based product. You will have to pay to enroll in its subscription. You can visit this link to download or know more about the product.
Summary Of The CVE-2022-23200 Vulnerability:
The flaw lice in improper parsing of 3GP files. Adobe said, affected versions of After Effects failed to properly validate user-supplied data, which can result in a write past the end of an allocated structure. This allows remote attackers to execute code in the context of the current process.
Researchers say that the flaw can’t be exploited without user interaction. Threat actors should trick the victim to visit a malicious page or open a malicious file to exploit the CVE-2022-23200 vulnerability.
After Effects Affected By The CVE-2022-23200 Vulnerability:
The vendor says that AE v22.1.1 and v18.4.3 and earlier are vulnerable to the CVE-2022-23200 Vulnerability. Users of Windows and Mac are urged to take action at the earliest.
Product
Version
Platform
Adobe After Effects
22.1.1 and earlier versions
Windows and macOS
Adobe After Effects
18.4.3 and earlier versions
Windows and macOS
How To Fix the ACE Vulnerability In Adobe After Effects CVE-2022-23200?
Adobe has responded to the vulnerability by releasing patches to fix it. Adobe recommends users update their After Effects to the latest available version. Here you can see the patched version details in the table.
Although you can download and apply the updates, Adobe recommends using the Creative Cloud desktop app. The app supports updating multiple Adobe products to the latest versions.
You can also use the Creative Cloud desktop app to enable auto-update, control auto-updates for individual apps, manual update of all or selected products.
Download and Install Creative Cloud desktop appDownload the Creative Cloud App from here. Then install the app using your registered Adobe account or email ID.
Select Preferences
Open the Creative Cloud desktop app. Click on the Account icon in the upper right, then select Preferences..
Configure the update settings for all or specific appsSelects the Aps tab the do any of the following.
All apps To set automatic updates for all apps, turn on Auto-update. Specific apps To choose the auto-update setting for specific apps, turn on Auto-update, then set the toggle as needed for each individual app.
The security research team from JFrog uncovered a remote code execution vulnerability in Apache Cassandra. The flaw is tracked under the CVE ID ‘CVE-2021-44521’ is assigned a base score of 8.4 allows attackers to perform remote code execution vulnerability on affected versions of Apache Cassandra database software. Since the vulnerability is easy to exploit and has the potential to wreak havoc on systems, it is very important to fix the CVE-2021-44521 vulnerability.
If you are using Cassandra database in any of your DevOps projects, please read this post. We have published this blog post to let you know how to fix the Apache Cassandra RCE vulnerability and how to mitigate the flaw in the case of being unable to apply the permanent fix.
Before we jump into the topic, it is necessary to understand certain aspects to learn about the flaw. Let’s get started.
What Is Apache Cassandra?
Apache Cassandra is a well-known NoSQL database developed in Java. Its Scalability and distributed nature made it extremely popular. Companies like Netflix, Twitter, Urban Airship, Constant Contact, Reddit, Cisco, OpenX, Digg, CloudKick, Ooyala, etc., will use this database extensively in their development projects. Its distributed nature made it more popular in DevOps and cloud-native development landscape. A well-known cloud-based turnkey solution DataStax (a serverless, multi-cloud DBaaS) is built on Cassandra.
What Is Nashorn Engine?
Since Cassandra is a NoSQL database, it stores data in JSON files. It uses User-Defined-Functions (UDFs) (written in Java and JavaScrip) to perform custom processing of data in the database. Nashorn is a JavaScript Engine that runs on top of the JVM, used to interpret UDFs written in JavaScripts.
Cassandra wrapped the Nashorn Engine with is a SandBox making Nashorn execution more secure. Or else anyone can abuse Nashorn by sending malicious untrusted code or UDFs.
How An Attacker Exploits Apache Cassandra RCE Vulnerability- CVE-2021-44521?
Report says that Attackers could exploit the Nashorn engine only with this non-default configuration set in the cassandra.yaml configuration file. Use your choice of text editor to edit the ‘/etc/cassandra/cassandra.yaml’ file.
$ sudo nano /etc/cassandra/cassandra.yaml
# Enable UDF support for both Java and JavaScript
enable_user_defined_functions: true
enable_scripted_user_defined_functions: true
# This is the key for the exploitation of CVE-2021-44521. It's default value is 'true'.
# true == Each invoked UDF function will run in a different thread, with a security manager without any permissions. Thsi lead to DoS attack.
# false == All invoked UDF functions run in the Cassandra daemon thread, which has a security manager with some permissions. This lead to SandBox escape and RCE.
enable_user_defined_functions_threads: false
When the flag enable_user_defined_functions_threads in cassandra.yaml file is set to false, attackers canescape the sandbox and achieve remote code execution.
Note: These flags can also be configured via the Config.java configuration file.
About the enable_user_defined_functions_threads Flag.
This is the key to the exploitation of CVE-2021-44521.
It’s default value is ‘true’.true == Each invoked UDF function will run in a different thread, with a security manager without any permissions. This will lead to a DoS attack.false == All invoked UDF functions run in the Cassandra daemon thread, which has a security manager with some permissions. This will lead to SandBox escape and RCE.
JFrog Security team says that “enable_user_defined_functions_threads is set to true by default, which means each invoked UDF function will run in a different thread, with a security manager without any permissions. This enables a malicious user to create a UDF that will shut down the Cassandra daemon. This is due to the behavior of the UDF timeout mechanism, governed by the user_defined_function_fail_timeout flag.
If a UDF function runs more than the allotted time, the entire Cassandra daemon will shut down. An attacker can easily DoS the entire database by creating a function which loops forever with while(true).
PoC Of Apache Cassandra RCE Vulnerability- CVE-2021-44521:
Kaspi published a PoC in the blog post. The researcher showed how a file named “hacked” is created on the Cassandra server.
How To Fix Apache Cassandra RCE Vulnerability- CVE-2021-44521?
Cassandra database addressed this vulnerability by adding a new flag allow_extra_insecure_udfs in v3.0.26, v3.11.12, and v4.0.2.
The flag allow_extra_insecure_udfs is set false by default, which prevent turning off the security manager and blocks UDFs to interact with elements outside the sandbox.
We recommend users of Apache Cassandra to upgrade to one of the following versions.
3.0.x users should upgrade to 3.0.26
3.11.x users should upgrade to 3.11.12
4.0.x users should upgrade to 4.0.2
How to upgrade Apache Cassandra on Linux?
There are a few simple prerequisites before upgrading Apache Cassandra database: 1. Take the system snapshot backup. 2. Remove all dead nodes. 3. Do not run nodetool repair or other tasks.
Flush all memtables from the nodeRun nodetool drain command before shut down the Cassandra service. This command will help in achieving these: 1. Flush all memtables from the node to SSTables on disk. 2. Stops listening for connections from the client and other nodes. 3. Prevents overcounts of counter data, and speeds up restart post-upgrade.
$ sudo nodetool drain -h hostname
Stop Cassandra services.
$ sudo systemctl status cassandra
Back up your Cassandra configuration files
Use this command to take the backup of cassandra.yaml
How to Mitigate Apache Cassandra RCE Vulnerability- CVE-2021-44521?
The vendor has recommended a few mitigations techniques for those who can’t apply the permanent patch soon.
If you are not using UDFs in your deployment, set these flags;
Set the flag enable_user_defined_functions to false to disable the UDF completely.
Set enable_user_defined_functions_threads to true if UDFs are needed.
Removing the following permissions: ALL FUNCTIONS, ALL FUNCTIONS IN KEYSPACE and FUNCTION for CREATE, ALTER and EXECUTE queries to remove the permissions of creating, altering and executing functions for untrusted users.
Conclusion
We hope this post will help you know How to Fix Apache Cassandra RCE Vulnerability- CVE-2021-44521. Thanks for reading this threat post. Please share this post and help to secure the digital world.
HOW GOOGLE WORKS: What began in the late 1990s as a research project helmed by Larry Page and Sergey Brin, two students in Stanford University’s Ph.D. program, is now one of the most influential companies in the world: Google. At first, the students’ goal was to make an efficient search engine that gave users relevant links in response to search requests.
While search is still Google’s core purpose, the company now provides services and goods ranging from (among many) email and photo storage to productivity software (the Google Docs suite), the internet browser Chrome, the mobile operating system Android, Chrome laptops and the Pixel mobile phone. Google has evolved from that two-man enterprise into a multibillion-dollar corporation. In 2015, it restructured and is now the jewel of parent company Alphabet, making it one of the biggest and richest companies in the world.
Google has long been the most visited site on the Web, too, making the company’s influence on commerce and culture undeniable [source: Lifewire]. Practically every webmaster wants his or her site listed high on Google’s search engine results pages (SERPs) because that almost always translates into more traffic. Google has also acquired other Internet companies, ranging from blogging services to YouTube. For a while, the company’s search technology even powered rival companies’ search engines: Yahoo relied on Google searches for nearly four years until developing its own search engine technologies in 2004 [source: Google].
In this article, we’ll learn about the backbone of Google’s business, its search engine. We’ll also look at other services Google offers. Then we’ll take a quick peek at some of the tools, both software and hardware, that Google has developed over the years. We’ll also learn more about the equipment Google uses to keep its massive operation running. Finally, we’ll take a closer look at Google, the company.
How Google Works Video
SOURCE: STUFFOFGENIUS
How Many Zeros?
Google’s name is a variation of the word “googol,” which is a mathematical term for a one followed by 100 zeros. Page and Brin felt the name helped illustrate Google’s monumental mission: Organizing billions of bytes of data found on the Web.
Blockchain analysis shows that funds paid in extortion are laundered through services primarily catering to Russian users.
Recently published research by Chainalysis shows that a staggering 74% of all ransomware revenue went to threat actors affiliated with Russia last year.
In other words, around $400 million worth of cryptocurrency ended up filling the pockets of cyber criminals connected to Russia in some form.
Unsurprisingly, researchers claim that Moscow’s financial district plays a critical role in soliciting money laundering activities for cybercriminals.
How do they know?
Researchers tie specific ransomware strains to Russia based on several criteria. One of the most obvious criteria is affiliations with EvilCorp, a Russia-based gang of cybercriminals with suspected ties to the Russian government.
Another indication of links to Russia is restraint from attacking countries that belong to the Commonwealth of Independent States (CIS), a block that unites nine former members of the Soviet Union.
“Many ransomware strains contain code that prevents the encryption of files if it detects the victim’s operating system is located in a CIS country,” reads the report.
In other cases, cybercriminals provided CIS-based organizations with decryptors instead of taking the ransom.
The third indicator of Russian affiliation is the language of a ransomware strain, location-specific settings, and other indicators linking beneficiary groups to Russia.
Three quarters
According to the researchers, blockchain analysis combined with web traffic data points to ransom revenue going to Russian users.
“Overall, roughly 74% of ransomware revenue in 2021 — over $400 million worth of cryptocurrency — went to strains we can say are highly likely to be affiliated with Russia in some way,” Chainalysis researchers claim.
26.4% of ransomware revenue is affiliated to Russia by CIS-avoiding criteria, while 9.9% went to EvilCorp, and 36.4% are affiliated via other Russian connections.
It is estimated that 13% of total ransomware revenue went to users directly in Russia, more than any other region.
Moscow City
An analysis of cryptocurrency businesses based in Moscow’s financial district, also known as Moscow City, points to companies partaking in money laundering activities.
According to Chainalysis, these businesses receive hundreds of millions of dollars worth of cryptocurrency per quarter, with totals peaking at nearly $1.2 billion in the second quarter of 2021.
It is estimated that illicit and risky addresses make up between 29% and 48% of all funds received by Moscow City crypto businesses.
“In total, across the three-year period studied, these businesses have received nearly $700 million worth of cryptocurrency from illicit addresses, which represents 13% of all value they’ve received in that time,” reads the report.
The majority of the illicit funds in Moscow City, $313 million, are linked to scams, while an additional $296 are attributed to darknet markets. Ransomware is estimated to add another $38 million to the mix.
The report claims that while some Moscow City-based crypto businesses are large enough to ‘miss’ the illicit funds due to large overall revenues, others can hardly be given the benefit of the doubt.
“But for other Moscow City cryptocurrency businesses, illicit funds make up as much as 30% or more of all cryptocurrency received, which suggests those businesses may be making a concerted effort to serve a cybercriminal clientele,” reads the report.
Moscow City towers. Image by Nikita Karimov, Unsplash.com.
It’s worth noting that more than half of crypto businesses suspected to be compliant in money laundering activities are based in the same building – the Federation Tower.
Golden age
Cyberattacks are increasing in scale, sophistication, and scope. The last 18 months were ripe with major high-profile cyberattacks, such as the SolarWinds hack, attacks against the Colonial Pipeline, meat processing company JBS, and software firm Kaseya.
Pundits talk of a ransomware gold rush, with the number of attacks increasing over 90% in the first half of 2021 alone.
The prevalence of ransomware has forced governments to take multilateral action against the threat. It’s likely a combined effort allowed to push the infamous REvil and BlackMatter cartels offline and arrest the Cl0p ransomware cartel members.
Recent arrests of Revil ransomware affiliates in Russia caused shockwaves in the criminal underground. The arrests made many threat actors uneasy since many felt local authorities would turn a blind eye if victims of ransomware attacks were outside Russia.
A recent report by Digital Shadows’ Photon Research Team shows concerns about possible arrests and confiscation of property became a lot more common.
Gangs, however, either rebrand or form new groups. Most recently, LockBit 2.0 was the most active ransomware group with a whopping list of 203 victims in Q3 of 2021 alone.
What a tangled web we weave, indeed. About 40 percent of the world’s population uses the Web for news, entertainment, communication and myriad other purposes [source: Internet World Stats]. Yet even as more and more people log on, they are actually finding less of the data that’s stored online. That’s because only a sliver of what we know as the World Wide Web is easily accessible.
The so-called surface Web, which all of us use routinely, consists of data that search engines can find and then offer up in response to your queries. But in the same way that only the tip of an iceberg is visible to observers, a traditional search engine sees only a small amount of the information that’s available — a measly 0.03 percent [source: OEDB].
As for the rest of it? Well, a lot of it’s buried in what’s called the deep Web. The deep Web (also known as the undernet, invisible Web and hidden Web, among other monikers) consists of data that you won’t locate with a simple Google search.
No one really knows how big the deep Web really is, but it’s hundreds (or perhaps even thousands) of times bigger that the surface Web. This data isn’t necessarily hidden on purpose. It’s just hard for current search engine technology to find and make sense of it.
There’s a flip side of the deep Web that’s a lot murkier — and, sometimes, darker — which is why it’s also known as the dark web. In the dark Web, users really do intentionally bury data. Often, these parts of the Web are accessible only if you use special browser software that helps to peel away the onion-like layers of the dark Web.
This software maintains the privacy of both the source and the destination of data and the people who access it. For political dissidents and criminals alike, this kind of anonymity shows the immense power of the dark Web, enabling transfers of information, goods and services, legally or illegally, to the chagrin of the powers-that-be all over the world.
Just as a search engine is simply scratching the surface of the Web, we’re only getting started. Keep reading to find out how tangled our Web really becomes.
Hidden in Plain Site
The deep Web is enormous in comparison to the surface Web. Today’s Web has more than 555 million registered domains. Each of those domains can have dozens, hundreds or even thousands of sub-pages, many of which aren’t cataloged, and thus fall into the category of deep Web.
Although nobody really knows for sure, the deep Web may be 400 to 500 times bigger that the surface Web [source: BrightPlanet]. And both the surface and deep Web grow bigger and bigger every day.
To understand why so much information is out of sight of search engines, it helps to have a bit of background on searching technologies.
Search engines generally create an index of data by finding information that’s stored on Web sites and other online resources. This process means using automated spiders or crawlers, which locate domains and then follow hyperlinks to other domains, like an arachnid following the silky tendrils of a web, in a sense creating a sprawling map of the Web.
This index or map is your key to finding specific data that’s relevant to your needs. Each time you enter a keyword search, results appear almost instantly thanks to that index. Without it, the search engine would literally have to start searching billions of pages from scratch every time someone wanted information, a process that would be both unwieldy and exasperating.
But search engines can’t see data stored to the deep Web. There are data incompatibilities and technical hurdles that complicate indexing efforts. There are private Web sites that require login passwords before you can access the contents. Crawlers can’t penetrate data that requires keyword searches on a single, specific Web site. There are timed-access sites that no longer allow public views once a certain time limit has passed.
All of those challenges, and a whole lot of others, make data much harder for search engines to find and index. Keep reading to see more about what separates the surface and deep Web.
If you think of the Web like an iceberg, the huge section below water is the deep Web, and the smaller section you can see above the water is the surface Web.
As we’ve already noted, there are millions upon millions of sub-pages strewn throughout millions of domains. There are internal pages with no external links, such as internal.howstuffworks.com, which are used for site maintenance purposes. There are unpublished or unlisted blog posts, picture galleries, file directories, and untold amounts of content that search engines just can’t see.
Here’s just one example. There are many independent newspaper Web sites online, and sometimes, search engines index a few of the articles on those sites. That’s particularly true for major news stories that receive a lot of media attention. A quick Google search will undoubtedly unveil many dozens of articles on, for example, World Cup soccer teams.
But if you’re looking for a more obscure story, you may have to go directly to a specific newspaper site and then browse or search content to find what you’re looking for. This is especially true as a news story ages. The older the story, the more likely it’s stored only on the newspaper’s archive, which isn’t visible on the surface Web. Subsequently, that story may not appear readily in search engines — so it counts as part of the deep Web.
If we can unlock the deep Web to search professional databases and difficult-to-access deep information, fields such as medicine would immediately benefit.
Data in the Deep Web is hard for search engines to see, but unseen doesn’t equal unimportant. As you can see just from our newspaper example, there’s immense value in the information tucked away in the deep Web.
The deep Web is an endless repository for a mind-reeling amount of information. There are engineering databases, financial information of all kinds, medical papers, pictures, illustrations … the list goes on, basically, forever.
And the deep Web is only getting deeper and more complicated. For search engines to increase their usefulness, their programmers must figure out how to dive into the deep Web and bring data to the surface. Somehow they must not only find valid information, but they must find a way to present it without overwhelming the end users.
As with all things business, the search engines are dealing with weightier concerns than whether you and I are able to find the best apple crisp recipe in the world. They want to help corporate powers find and use the deep Web in novel and valuable ways.
For example, construction engineers could potentially search research papers at multiple universities in order to find the latest and greatest in bridge-building materials. Doctors could swiftly locate the latest research on a specific disease.
The potential is unlimited. The technical challenges are daunting. That’s the draw of the deep Web. Yet there’s a murkier side to the deep Web, too — one that’s troubling to a lot of people for a lot reasons.
Darkness Falls
The deep Web may be a shadowland of untapped potential, but with a bit of skill and some luck, you can illuminate a lot of valuable information that many people worked to archive. On the dark Web, where people purposely hide information, they’d prefer it if you left the lights off.
The dark Web is a bit like the Web’s id. It’s private. It’s anonymous. It’s powerful. It unleashes human nature in all its forms, both good and bad.
The bad stuff, as always, gets most of the headlines. You can find illegal goods and activities of all kinds through the dark Web. That includes illicit drugs, child pornography, stolen credit card numbers, human trafficking, weapons, exotic animals, copyrighted media and anything else you can think of. Theoretically, you could even, say, hire a hit man to kill someone you don’t like.
But you won’t find this information with a Google search. These kinds of Web sites require you to use special software, such as The Onion Router, more commonly known as Tor.
Tor is software that installs into your browser and sets up the specific connections you need to access dark Web sites. Critically, Tor is an encrypted technology that helps people maintain anonymity online. It does this in part by routing connections through servers around the world, making them much harder to track.
Tor also lets people access so-called hidden services — underground Web sites for which the dark Web is notorious. Instead of seeing domains that end in .com or .org, these hidden sites end in .onion. On the next page we’ll peel back the layers of some of those onions.
In October 2013, U.S. authorities shut down Silk after the alleged owner of the site Ross William Ulbricht was arrested.
The most infamous of these onion sites was the now-defunct Silk Road, an online marketplace where users could buy drugs, guns and all sorts of other illegal items. The FBI eventually captured Ross Ulbricht, who operated Silk Road, but copycat sites like Black Market Reloaded are still readily available.
Oddly enough, Tor is the result of research done by the U.S. Naval Research Laboratory, which created Tor for political dissidents and whistleblowers, allowing them to communicate without fear of reprisal.
Tor was so effective in providing anonymity for these groups that it didn’t take long for the criminally-minded to start using it as well.
That leaves U.S. law enforcement in the ironic position of attempting to track criminals who are using government-sponsored software to hide their trails. Tor, it would seem, is a double-edged sword.
Anonymity is part and parcel on the dark Web, but you may wonder how any money-related transactions can happen when sellers and buyers can’t identify each other. That’s where Bitcoin comes in.
If you haven’t heard of Bitcoin, it’s basically an encrypted digital currency. Like regular cash, Bitcoin is good for transactions of all kinds, and notably, it also allows for anonymity; no one can trace a purchase, illegal or otherwise.
Bitcoin may be the currency of the future — a decentralized and unregulated type of money free of the reins of any one government. But because Bitcoin isn’t backed by any government, its value fluctuates, often wildly. It’s anything but a safe place to store your life savings. But when paired properly with Tor, it’s perhaps the closest thing to a foolproof way to buy and sell on the Web.
The dark Web is home to alternate search engines, e-mail services, file storage, file sharing, social media, chat sites, news outlets and whistleblowing sites, as well as sites that provide a safer meeting ground for political dissidents and anyone else who may find themselves on the fringes of society.
The dark Web has its ominous overtones. But not everything on the dark side is bad. There are all sorts of services that don’t necessarily run afoul of the law.
In an age where NSA-type surveillance is omnipresent and privacy seems like a thing of the past, the dark Web offers some relief to people who prize their anonymity. Dark Web search engines may not offer up personalized search results, but they don’t track your online behavior or offer up an endless stream of advertisements, either. Bitcoin may not be entirely stable, but it offers privacy, which is something your credit card company most certainly does not.
For citizens living in countries with violent or oppressive leaders, the dark Web offers a more secure way to communicate with like-minded individuals. Unlike Facebook or Twitter, which are easy for determined authorities to monitor, the dark Web provides deeper cover and a degree of safety for those who would badmouth or plot to undermine politicians or corporate overlords.
A paper written by researchers at the University of Luxembourg attempted to rank the most commonly accessed materials on the dark Web. What they found was that although sites trading in illegal activities and adult content are very popular, so too are those concerned with human rights and freedom of information [Source: ArXiv].
So although the dark Web definitely has its ugly side, it has great potential, too.
Even Deeper
The deep Web is only getting deeper. Its store of human knowledge and trivialities grows more massive every day, complicating our efforts to make sense of it all. In the end, that’s perhaps the biggest challenge behind the Internet that we’ve created.
Programmers will continue to improve search engine algorithms, making them better at delving into deeper layers of the Web. In doing so, they’ll help researchers and businesses connect and cross-reference information in ways that were never possible before.
At the same time, the primary job of a smart search engine is not to simply find information. What you really want it to do is find the most relevant information. Otherwise, you’re left awash in a sea of cluttered data that leaves you wishing you had never clicked on that search button.
That’s the problem of so-called big data. Big data is the name for sets of data that are so large that they become unmanageable and incoherent. Because the Internet is growing so quickly, our whole world is overrun with data, and it’s hard for anyone to make sense of it all — even all of those powerful, all-knowing computers at Bing and Google headquarters.
As the Internet grows, every large company spends more and more money on data management and analysis, both to keep their own organizations functioning and also to obtain competitive advantages over others. Mining and organizing the deep Web is a vital part of those strategies. Those companies that learn to leverage this data for their own uses will survive and perhaps change the world with new technologies. Those that rely only on the surface Web won’t be able to compete.
In the meantime, the deep Web will continue to perplex and fascinate everyone who uses the Internet. It contains an enthralling amount of knowledge that could help us evolve technologically and as a species when connected to other bits of information. And of course, its darker side will always be lurking, too, just as it always does in human nature. The deep Web speaks to the fathomless, scattered potential of not only the Internet, but the human race, too.
Lots More Information
Author’s Note: How the Deep Web Works
The Deep Web is a vague, ambiguous place. But while researching this story, it was easy to conclude at least one thing for sure — most news headlines tend to sensationalize the dark Web and its seedier side, and rarely mention the untapped potential of the deep Web. Articles about illegal drugs and weapons obviously draw more readers than those detailing the technical challenges of harvesting data from the deep Web. Read the negative, breathless articles with a grain of salt. It’s worth remembering that there’s a whole lot more to the deep Web than the obvious criminal element. As engineers find better, faster ways to catalog the Web’s stores of data, the Internet as a whole could transform our society in amazing ways.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of the cookies. Cookie & Privacy Policy
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.