Ransomware gang coughs up decryptor after realizing they hit the police
The AvosLocker ransomware operation provided a free decryptor after learning they encrypted a US government agency. Last month, a US police department was breached by AvosLocker, who encrypted devices and stole data during the attack.
However, according to a screenshot shared by security researcher pancak3, after learning that the victim was a government agency, they provided a decryptor for free.
image
When asked if they purposely avoid targeting government agencies out of fear of law enforcement, they said it’s more because “tax payer money’s generally hard to get.”
However, international law enforcement operations have resulted in numerous indictments or arrests of ransomware members and money launderers over the past year. These arrests include members of the REvil, Netwalker, and Clop ransomware gangs.
One of the items benchmarking tools like GTMetrix and Google PageSpeed Insights rate your site for, is whether it leverages browser caching or not.
Often these tools reveal more pressing matters to concern yourself with, that have a larger impact on the benchmarking score. Practices like optimizing images and minifying CSS, HTML, and JavaScript, for instance.
On the other hand, I’m not a server-side expert, but I found that achieving a better score on these tools – and getting a slightly faster page load – by adding just a couple of lines to your .htaccess file to enable browser caching is quite simple.
Here’s how I did it.
How does browser caching work
Your site contains files that change often and some that change not so often. Some files hardly – if ever – change.
When you place an image on your site, that image will almost never change. Same with video files. JavaScript files, like those that your theme or plugins use, change more often. PDF files also tend to change more often.
CSS files generally change most often, especially when you’re a designer or developer. Visitors need a fresh copy of those on their computer since CSS files change the look of your site.
When a person visits your site, their browser downloads these files and saves them on their hard drive. Plus, for each of these files, the browser sends a separate request to the server. This all adds to a load of your server, slowing it down. Especially image files and video add to the load.
With browser caching turned on, not all of these files will be requested and downloaded again when your visitor clicks on another page on your site that uses the same files or revisits your site later. Their computer uses the stored files instead of downloading the same files again. This practice helps your site load faster for that visitor since these downloaded files and file requests don’t need to be transferred over the internet again.
By the way, the effect of browser caching on page loading times depends greatly on the size of your pages. When your site is image-heavy, and the visitor’s browser needs to download large files from your site, the effect is greater than when your site takes a more minimalist approach.
Now, adding browser caching doesn’t totally solve the issue these tools report. Some external .js files, like Google Analytics and Google Fonts, do not allow caching, but your site will score better with browser caching enabled.
It took me a long time to figure out the best caching setup for my WordPress sites on Apache servers. And I am open to changes in the future when technology changes.
How do you add browser caching to your site’s setup
Browser caching rules tell the browser whether a file only needs refreshing once a year, once a month, or whatever time you decide is appropriate for your situation. Refreshing, in this case, means downloading it again.
The rules that tell the browser when to download which files are set in the .htaccess file in the root of your site.
Note: messing around in your .htaccess file is a great way to bring your site down. Always, always, always make sure you download a copy of your working .htaccess file before you change anything in the file.
Using Expires headers for browser caching
Until recently, I used the recommended settings GTmetrix prescribes on their site.
For these settings, GTmetrix takes the approach that:
image and video files change least often, so these will download again after a year since the last downloaded version
JavaScript, and PDF files change a little more frequently, so these will download after a month
CSS files change most often, so need downloading after a week
all other files will download again after a month
Caveat: I noticed some problems with forms on a site using a general one-month expiry, so I took that rule out.
# BROWSER CACHING USING EXPIRES HEADERS
<IfModule mod_expires.c>
ExpiresActive On
# Images
ExpiresByType image/jpeg "access plus 1 year"
ExpiresByType image/gif "access plus 1 year"
ExpiresByType image/png "access plus 1 year"
ExpiresByType image/webp "access plus 1 year"
ExpiresByType image/svg+xml "access plus 1 year"
ExpiresByType image/x-icon "access plus 1 year"
# Video
ExpiresByType video/mp4 "access plus 1 year"
ExpiresByType video/mpeg "access plus 1 year"
# CSS, JavaScript
ExpiresByType text/css "access plus 1 week"
ExpiresByType text/javascript "access plus 1 month"
ExpiresByType application/javascript "access plus 1 month"
# Others
ExpiresByType application/pdf "access plus 1 month"
ExpiresByType application/x-shockwave-flash "access plus 1 month"
</IfModule>
The solution GTmetrix prescribes uses Expires headers that specify expiration times for specific file extensions to the browser. This way, the browser knows when to download a fresh copy of a specific file.
When added to the .htaccess file, these rules turn on browser caching without any problems.
However, there is another – and apparently better – way.
Using Cache-Control headers for browser caching
I recently came across this article on using Cache-Control headers for browser caching.
Cache-Control headers replaces Expires headers is more flexible (accepts more directives), and is currently the preferred method for browser caching.
Since all modern browsers support Cache-Control headers, you should only need to add these lines to your .htaccess file:
# BROWSER CACHING USING CACHE-CONTROL HEADERS
<ifModule mod_headers.c>
# One year for image and video files
<filesMatch ".(flv|gif|ico|jpg|jpeg|mp4|mpeg|png|svg|swf|webp)$">
Header set Cache-Control "max-age=31536000, public"
</filesMatch>
# One month for JavaScript and PDF files
<filesMatch ".(js|pdf)$">
Header set Cache-Control "max-age=2592000, public"
</filesMatch>
# One week for CSS files
<filesMatch ".(css)$">
Header set Cache-Control "max-age=604800, public"
</filesMatch>
</ifModule>
As you can see, I’m using the exact same file expiration settings in these Cache-Control headers as in the Expires headers example. All max-age values are in seconds, e.g. one month equals:
60 (seconds in a minute) x 60 (minutes in an hour) x 24 (hours in a day) x 30 (average number of days in a month) = 2592000
The Cache-Control header was defined as part of the HTTP/1.1 specification and supersedes previous headers (for example, Expires) used to define response caching policies. All modern browsers support Cache-Control, so that’s all you need.
Google Developers website
Fail-safe method for setting browser caching in your .htaccess file
However, Dutch hosting provider Byte describes using both Expires headers and Cache-Control headers on their servers, to ensure proper browser caching on servers that may not support one. This might, for now, be the fail-safe method of choice, and what I’m using for my own and my client’s sites:
# BROWSER CACHING USING EXPIRES HEADERS
<IfModule mod_expires.c>
ExpiresActive On
# Images
ExpiresByType image/jpeg "access plus 1 year"
ExpiresByType image/gif "access plus 1 year"
ExpiresByType image/png "access plus 1 year"
ExpiresByType image/webp "access plus 1 year"
ExpiresByType image/svg+xml "access plus 1 year"
ExpiresByType image/x-icon "access plus 1 year"
# Video
ExpiresByType video/mp4 "access plus 1 year"
ExpiresByType video/mpeg "access plus 1 year"
# CSS, JavaScript
ExpiresByType text/css "access plus 1 week"
ExpiresByType text/javascript "access plus 1 month"
ExpiresByType application/javascript "access plus 1 month"
# Others
ExpiresByType application/pdf "access plus 1 month"
ExpiresByType application/x-shockwave-flash "access plus 1 month"
</IfModule>
# BROWSER CACHING USING CACHE-CONTROL HEADERS
<ifModule mod_headers.c>
# One year for image and video files
<filesMatch ".(flv|gif|ico|jpg|jpeg|mp4|mpeg|png|svg|swf|webp)$">
Header set Cache-Control "max-age=31536000, public"
</filesMatch>
# One month for JavaScript and PDF files
<filesMatch ".(js|pdf)$">
Header set Cache-Control "max-age=2592000, public"
</filesMatch>
# One week for CSS files
<filesMatch ".(css)$">
Header set Cache-Control "max-age=604800, public"
</filesMatch>
</ifModule>
Disabling ETag: yes or no
The Byte article also recommended disabling ETag by adding these lines to the .htaccess file:
A St. Louis Post-Dispatch reporter who viewed the source HTML of a Missouri Department of Elementary and Secondary Education website is now likely to be prosecuted for computer tampering, says Missouri Governor Mike Parson.
All web browsers have a “view source” menu item that lets you see the HTML code of the web page it is displaying.
The reporter discovered that the source code of the website contained Social Security numbers of educators. The reporter alerted the state about the social security numbers. After the state removed the numbers from the web page, the Post-Dispatch reported the vulnerability.
Soon after, Governor Parson, “who has often tangled with news outlets over reports he doesn’t like, announced a criminal investigation into the reporter and the Post-Dispatch.”
“If somebody picks your lock on your house — for whatever reason, it’s not a good lock, it’s a cheap lock or whatever problem you might have — they do not have the right to go into your house and take anything that belongs to you,” Parson said in a statement.
A commenter on the Post-Dispatch story offers a more apt analogy:
A better analogy would be you’re walking in the street past a neighbor’s house and notice their front door wide open with no one around. You can see a purse and car keys near the door. You phone that neighbor, and tell them their door is open and their purse and keys are easily visible from the street. Would Parson consider this breaking and entering?
[A] state cybersecurity specialist informed Sandra Karsten, the director of the Department of Public Safety, that an FBI agent said the incident “is not an actual network intrusion.”
Instead, the specialist wrote, the FBI agent said the state’s database was “misconfigured,” which “allowed open source tools to be used to query data that should not be public.”
“These documents show there was no network intrusion,” St. Louis Post-Dispatch President and Publisher Ian Caso said this month. “As DESE initially acknowledged, the reporter should have been thanked for the responsible way he handled the matter and not chastised or investigated as a hacker.”
Enjoyed this post?
Why not subscribe to our weekly cybersecurity newsletter?
You may have heard that Telegram has released arguably their biggest update of the year this week. While the backend of the messaging platform remains proprietary, the source code of the mobile and desktop clients is open source.
The big new feature is Message Translations, which allows the translation of text messages within the app. What is interesting is how this is implemented in the official Android app.
How the Telegram Android app circumvents the official Google Cloud Translate API
Undocumented Google Translate API endpoint
If you check the official Cloud Translate REST API documentation, you will see that the official API uses a versioned API path (e.g. /language/translate/v2), and human readable query parameters, which importantly include the API key key. If we check Telegram’s implementation, we will notice a few things in the fetchTranslation method:
They use another path, and also seem to intentionally split up the request path. There is multiple string joins (perhaps for obscurity / avoid detection in the Play Store review process?
uri = "https://translate.goo";
uri += "gleapis.com/transl";
uri += "ate_a";
uri += "/singl";
uri += "e?client=gtx&sl=" + Uri.encode(fromLanguage) + "&tl=" + Uri.encode(toLanguage) + "&dt=t" + "&ie=UTF-8&oe=UTF-8&otf=1&ssel=0&tsel=0&kc=7&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&q=";
uri += Uri.encode(text.toString());
We can deduce from the query string that:
client is some kind of client caller specifier (e.g. webapp / native app?)
sl and tl are source and target languages
ie and oe are input and output encoding of the text data
ssel and tsel have something to do with text selection?
q is the query text (the URI encoded text to actually translate)
UPDATE: This workaround is explained very well in this blog post, so definitely check it out.
User agent rotation
Another thing I noticed is that Telegram keeps an array of strings containing various User Agents, with comments indicating percentages (what they represent is not clear to me at the moment):
private String[] userAgents = new String[] {
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36", // 13.5%
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36", // 6.6%
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0", // 6.4%
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0", // 6.2%
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36", // 5.2%
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36" // 4.8%
};
In the same method, it seems that they randomly pull a user agent from this array and pass it to the request to Google:
It seems like a classic example of user agent rotation, a technique often used by web scrapers to avoid being rate limited / blacklisted by web services.
Conclusion
It seems that to get around the problem of translating text on Android in Telegram and not pay huge Google Cloud fees and risk leaking their API key, Telegram found some obscure way of querying the Cloud Translate API directly at no cost to them.
My advice would be to simply use their pre-built official Java SDK, and utilize RPC over HTTP to save on bandwidth (which will be very substantial given Telegram’s over 500 million active users. To me it seems the feature was heavily rushed in time for the end of the year, given the state of the new code linked above.
apparently, the advanced nmt model is already used here. but what API does Google Chrome use internally to translate the content and can this API be accessed directly – even on the server-side? to analyze network traffic, tools like Wireshark or Telerik Fiddler are recommended, which can also analyze encrypted traffic. but Chrome even delivers the requests it sends during page translation free of charge: they can be easily viewed via the Chrome DevTools:
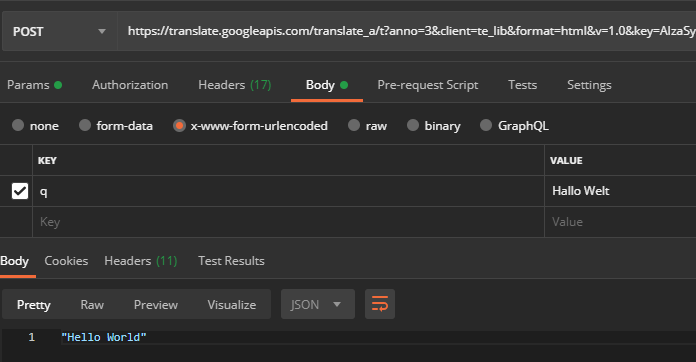
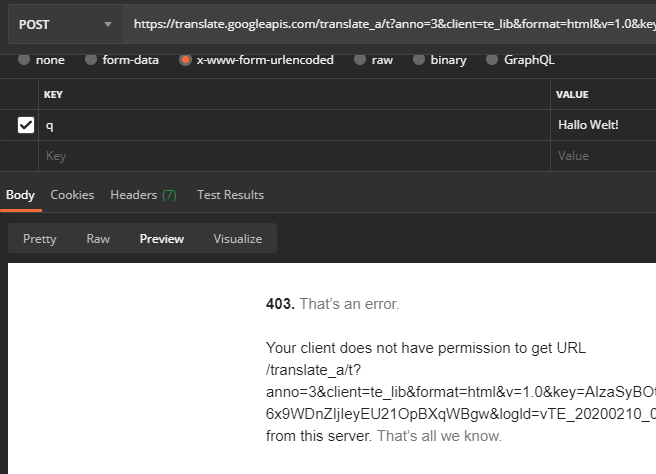
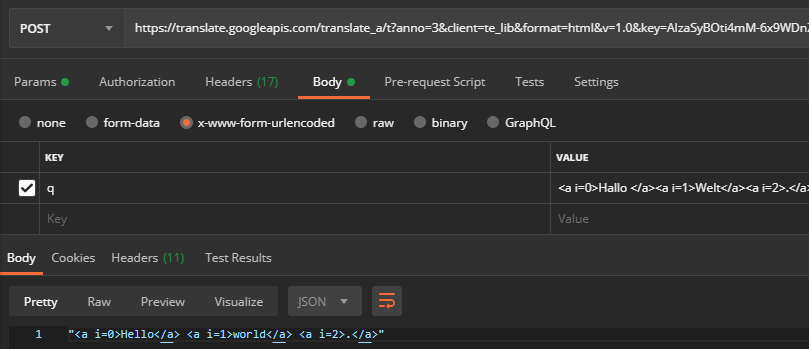
If you do a translation, then catch the decisive POST request https://translate.googleapis.com via “Copy > Copy as cURL (bash)” and execute it in a tool like Postman, for example, you can resend the request without any problems:
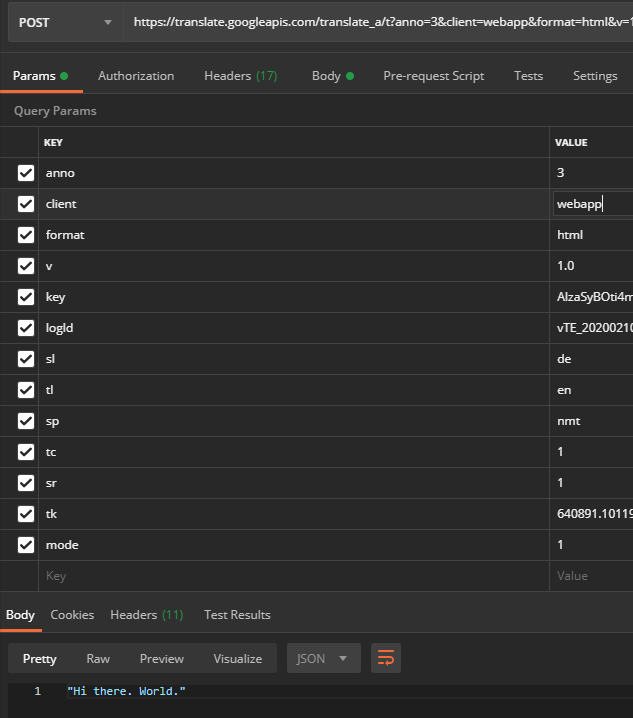
The meaning of the URL parameters are also largely obvious:
Key
Example Value
Meaning
anno
3
Annotation mode (affects the return format)
client
te_lib
Client information (varies, via the web interface of Google-Translate the value is “webapp”; affects the return format and the rate limiting)
format
html
String format (important for translating HTML tags)
v
1.0
Google Translate version number
key
AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw
API key (see below)
logld
vTE_20200210_00
Protocol version
sl
en
Source language
tl
en
Target language
sp
nmt
ML model
tc
1
unknown
sr
1
unknown
tk
709408.812158
Token (see below)
fashion
1
unknown
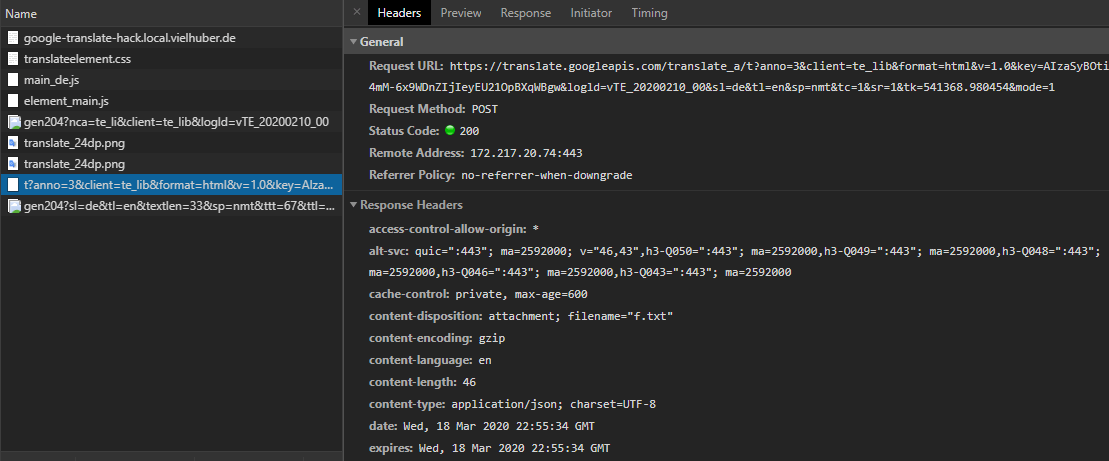
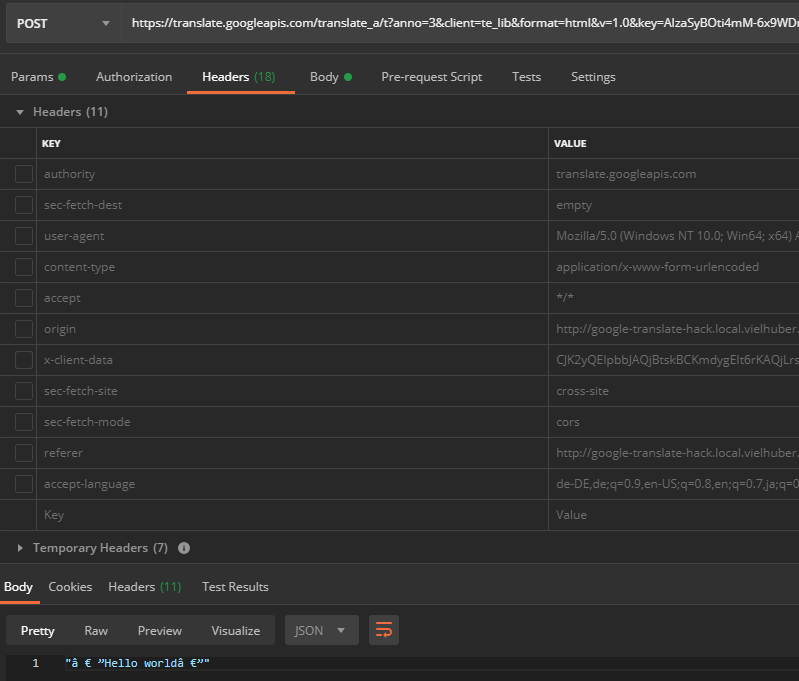
Some request headers are also set – but these can mostly be ignored. After manually deselecting all headers, including those from the user agent , an encoding problem is discovered when entering special characters (here when translating ” Hello World “):
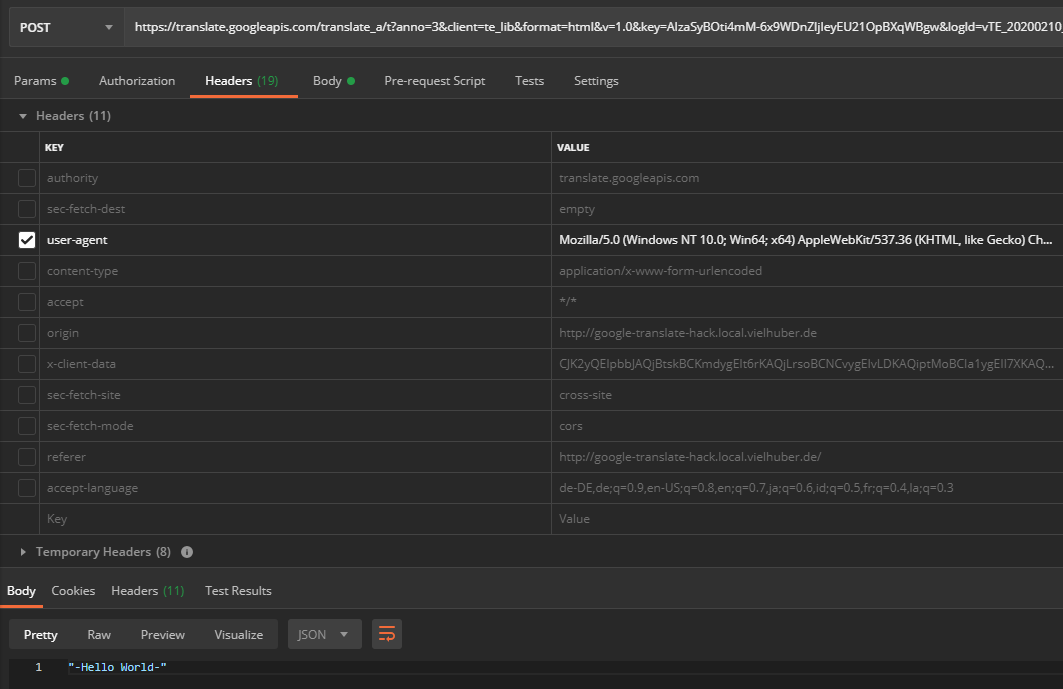
If you reactivate the user agent (which generally doesn’t do any harm), the API delivers UTF-8 encoded characters:
Now that we have all the information we need to use this API outside of Google Chrome, if we change the string to be translated (data field q of the POST request) from, for example, “Hello World” to “Hello World“, we get an error message:
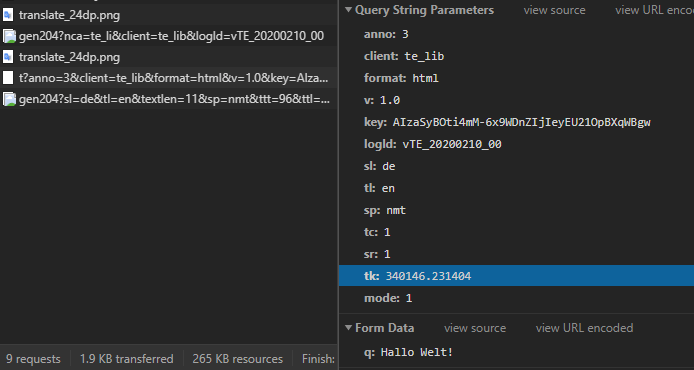
We now retranslate this modified one within Google Chrome using the web page translation function and find that the parameter tk has changed as well as the parameter q (all other parameters have remained the same):
Obviously, it is a string dependent token, whose structure is not easy to see, but when you start the web page translation, the following files are loaded:
1 CSS file: translateelement.css
4 graphics: translate_24dp.png (2x), gen204 (2x)
2 JS files: main_de.js , element_main.js
The two JavaScript files are obfuscated and minified. Tools like JS Nice and de4js are now helping us to make these files more readable. In order to debug them live, we recommend the Chrome Extension Request, which tunnels remote files locally on the fly:
Now we can debug the code ( CORS must be enabled on the local server) The relevant code section for generating the token seems to be hidden in the file element_main.js in this section:
function Bp(a, b) {
var c = b.split(“.”);
b = Number(c[0]) || 0;
for (var d = [], e = 0, f = 0; f < a.length; f++) {
var h = a.charCodeAt(f);
128 > h ? d[e++] = h : (2048 > h ? d[e++] = h >> 6 | 192 : (55296 == (h & 64512) && f + 1 < a.length && 56320 == (a.charCodeAt(f + 1) & 64512) ? (h = 65536 + ((h & 1023) << 10) + (a.charCodeAt(++f) & 1023), d[e++] = h >> 18 | 240, d[e++] = h >> 12 & 63 | 128) : d[e++] = h >> 12 | 224, d[e++] = h >> 6 & 63 | 128), d[e++] = h & 63 | 128)
}
a = b;
for (e = 0; e < d.length; e++) a += d[e], a = Ap(a, “+-a^+6”);
a = Ap(a, “+-3^+b+-f”);
a ^= Number(c[1]) || 0;
0 > a && (a = (a & 2147483647) + 2147483648);
c = a % 1E6;
return c.toString() +
“.” + (c ^ b)
}
Here, among other things, the text is hashed with the help of some bit shifts. But unfortunately, we are still missing a piece of the puzzle: To the function Bp(), besides the argument a (which is the text to be translated), another argument b is passed – a kind of seed, which seems to change over time to time and which is also included in the hashing. But where does it come from? If we jump to the function call of Bp(), we find the following code section:
Tr.prototype.translate = function (a, b, c, d, e, f, h, k) {
null != r && (n.jwtt = r, n.rurl = location.hostname);
return l.a.na.send(n, C(Wr(m), l))
}, function (r) {
r && l.Vb && l.Vb(r)
}) : this.a.na.send(n, m)
};
The function Hq is previously declared as follows:
Hq = function () {
function a(d) {
return function () {
return d
}
}
var b = String.fromCharCode(107),
c = a(String.fromCharCode(116));
b = a(b);
c = [c(), c()];
c[1] = b();
return yq[“_c” + c.join(b())] || “”
}(),
Here the Deobfuscater left some rubbish; After we have replaced String.fromCharCode (‘…’) with the respective character strings, remove the obsolete a () and piece together the function calls [c (), c ()] , the result is:
Hq = function () {
var b = ‘k’,
c = ‘t’;
c = [c, c];
c[1] = b();
return yq[‘_c’ + c.join(b())] || ”
}(),
Or even easier:
Hq = function () {
return yq[‘_ctkk’] || ”
}(),
The function yq is previously defined as:
var yq = window.google && google.translate && google.translate._const;
So the seed seems to be in the global object google.translate._const._ctkk, which is available at runtime. But where is it set? In the other, previously loaded JS-file main_en.js at least it is also available at the beginning. For this we add the following at the beginning:
In the console we now actually get the current seed:
This leaves Google Chrome itself, which apparently provides the seed, as the last option. Fortunately, its source code (Chromium, including the Translate component) is open source and therefore publicly available. We pull the repository locally and find the call to the TranslateScript :: GetTranslateScriptURL function in the translate_script.cc file in the components / translate / core / browserfolder:
GURL TranslateScript::GetTranslateScriptURL() {
GURL translate_script_url;
// Check if command-line contains an alternative URL for translate service.
const base::CommandLine& command_line =
*base::CommandLine::ForCurrentProcess();
if (command_line.HasSwitch(translate::switches::kTranslateScriptURL)) {
If we now examine the element.js file more closely (after deobfuscating again), we find the hard-set entry c._ctkk – the google.translate object is also set accordingly and the loading of all relevant assets (which we have already discovered earlier) is triggered:
function _setupNS(b) {
b = b.split(“.”);
for (var a = window, c = 0; c < b.length; ++c) a.hasOwnProperty ? a.hasOwnProperty(b[c]) ? a = a[b[c]] : a = a[b[c]] = {} : a = a[b[c]] || (a[b[c]] = {});
Now the parameter key remains for consideration (with the value AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw). That seems to be a generic browser API key (which can also be found in some Google results ). It is set in Chromium in the file translate_url_util.cc in the folder components / translate / core / browser:
The key is generated in google_apis / google_api_keys.cc from a dummy value:
#if !defined(GOOGLE_API_KEY)
#define GOOGLE_API_KEY DUMMY_API_TOKEN
#endif
However, a test shows that the API calls work the same without this key parameter. If you experiment with the API, you will get the status code 200 back if you are successful. If you then run into a limit, you get the status code 411 back with the message ” POST requests require a content-length header “. It is therefore advisable to include this header (which is automatically set as a temporary header in Postman).
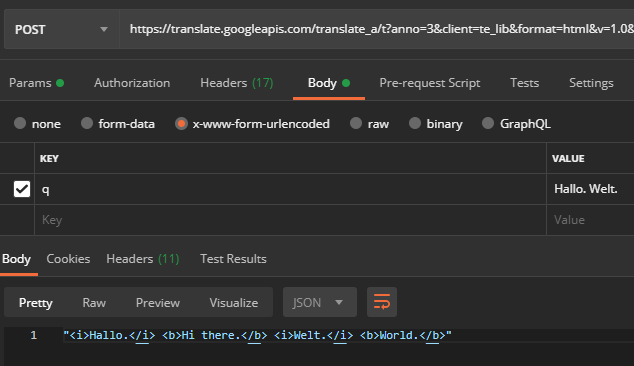
The return format of the translated strings is unusual when there are several sentences in one request, and the individual sentences are enclosed by the i-/b-HTML tags:
Also, Google Chrome does not send all the HTML to the API, but saves attribute values such as href in the request (and sets indexes instead, so that the tags can be assigned again later on the client side):
If you change the value of the POST key client from te_lib (Google Chrome)on webapp ( Google Translation website ), you get the final translated string:
The problem is that you are much more likely to run into rate limiting than via te_lib (for comparison: with webapp this is reached after 40,000 chars, with te_lib there is no rate limiting). So we need to take a closer look at how Chrome parses the result. We’ll find it here in element_main.js:
x.Pf = function (a, b) {
b.g && this.l.remove(b.f);
if (!this.b) return !1;
if (this.l.has(b.ea(), !1)) {
var c = this.l;
if (c.has(b.f, !1)) {
var d = b.f,
e = c.a[d];
e || (e = c.b[d], c.a[d] = e);
b.b = e;
b.K = !0
} else c.remove(b.f), b.g = !0;
zt(b)
} else if (c = this.l, b.g) c.remove(b.f);
else if (b.o) {
d = b.o.replace(/<a /g, “<span “).replace(/\/a>/g, “/span>”);
b.K = !0;
delete b.o;
b.o = null;
b.b = [];
e = jg(document, Za);
Q(e, !1);
e.innerHTML = 0 <= d.indexOf(“<i>”) ? d : “<b>” + d + “</b>”;
document.body.appendChild(e);
d = [];
var f;
for (f = e.firstChild; f; f = f.nextSibling)
if (“I” ==
f.tagName) var h = yt(b, Kg(f), f.innerHTML);
else if (“B” == f.tagName) {
h || (h = yt(b, “”, “”));
if (1 == b.a.length) xt(h.$, d, 0, f);
else {
var k = d;
var l = f;
var m = b.a;
h = h.$;
for (var n = [], r, w = l.firstChild; w; w = r) r = w.nextSibling, Ct(w);
for (k = 0; k < f.length – 1; ++k) m = f[k], h = ze(m.$[m.$.length – 1].T), h = h.charCodeAt(h.length – 1), 12288 <= h && 12351 >= h || 65280 <= h && 65519 >= h || (m.$[m.$.length – 1].T += ” “);
sg(e);
for (e = 0; e < b.a.length; ++e) e < d.length && e < b.l.length && null != d[e] && (f = b.l[e], k = d[e].start, null != k && (m = f.substring(0, f.length – ye(f).length), ” ” == m && (m = “”), m && (k.T = m + ye(k.T))), k = d[e].end, null != k && (f = f.substring(ze(f).length), ” ” == f && (f = “”), f && (k.T =
if (a.o != b || c) a.o = b, a.L ? (a.l(a.o, !0, c), a.W(a.K)) : a.l(a.o, !1, c);
return !1
};
If you send the entire HTML code to the API, it leaves the attributes in the translated response. We therefore do not have to imitate the entire parse behavior, but only extract the final, translated string from the response. To do this, we build a small HTML tag parser that discards the outermost <i> tags including their content and removes the outermost <b> tags. With this in mind, we can now build a server-side version of the translation API:
The following are the results of an initial test that was carried out on five different systems with different bandwidths and IP addresses:
Character
Characters per request
Duration
Error rate
Cost via official API
13.064.662
~250
03: 36: 17h
0%
237,78€
24.530.510
~250
11: 09: 13h
0%
446,46€
49.060.211
~250
20:39:10h
0%
892,90€
99.074.487
~1000
61: 24: 37h
0%
1803,16€
99.072.896
~1000
62:22:20h
0%
1803,13€
Σ284.802.766
~ Ø550
Σ159:11:37h
0%
Σ € 5183.41
Note: This blog post, including all scripts, was written for testing purposes only; do not use the scripts for productive use, but work with the official Google Translation API instead.
“I see that the Log4Shell vulnerability, which has transformed into multiple vulnerabilities, is going to stay with us for a while”. Just yesterday, December 28th, yet another remote code execution vulnerability was discovered again in all Log4j versions, with a new fix now available in v2.17.1. Is log4shell really the worst security issue of the decade?
So, here is the latest update of what we know so far, at the time of writing, with the latest information.
Is Log4Shell the worst security issue in decades?
December 10, 2021 – The original Log4Shell vulnerability was disclosed under CVE-2021-44228 with the possibility for an attacker to execute injected code using the message lookup functionality. Affected versions were Log4j v2.0-2.14.1.
December 13, 2021 – The second vulnerability disclosed under CVE-2021-45046 could allow attackers to craft malicious input data that could cause an information leak, remote code execution, and denial-of-service (DoS).
December 16, 2021 – The third vulnerability disclosed under CVE-2021-45105 could allow an attacker to initiate a denial-of-service (DoS) attack by causing an infinite recursion loop on self-referential lookups.
December 28, 2021 – The fourth vulnerability disclosed under CVE-2021-44832 could allow an attacker with permission to modify the logging configuration file to construct a malicious configuration using a JDBC Appended with a data source referencing a JNDI URI that can execute remote code.
Log4Shell the worst security issue in decades?
What can you do against the Log4shell vulnerability?
Identify – Identifying assets affected by Log4Shell and other Log4j-related vulnerabilities.
Patch – Upgrading Log4j assets and affected products to the latest available version.
Hunt– Initiating hunt and incident response procedures to detect possible Log4Shell exploitation.Log4j Log4Shell scanner to find vulnerable apps
On December 21st, the Cybersecurity and Infrastructure Security Agency (CISA) announced the release of a scanner for identifying web services impacted by two Apache Log4j remote code execution vulnerabilities, tracked as CVE-2021-44228 and CVE-2021-45046.
According to the agency, “log4j-scanner is a project derived from other members of the open-source community by CISA’s Rapid Action Force team to help organizations identify potentially vulnerable web services affected by the log4j vulnerabilities.”
It’s highly recommended to use the scanning tool to identify services affected by Log4j vulnerabilities and to patch them to the latest Log4j version, which is 2.17.1.
Other mitigation recommendations you can consider when updating Log4j isn’t an option:
Deploy detection and prevention Web Application Firewall (WAF) and Intrusion Prevention Systems (IPS) rules. While threat actors will be able to bypass this mitigation, the reduction in alerting will allow the organizational Security Operations Center (SOC) to focus on a smaller set of alerts.
Reducing the attack surface by blocking the standard ports for LDAP, LDAPS, and RMI (389, 636, 1099, 1389). Although this isn’t bulletproof, as the ports can be randomized, this can still reduce the attack surface.
Disable the Log4j library. Disabling software using the Log4j library is an effective measure, favoring controlled downtime over adversary-caused issues. This option, however, could have operational impacts and limit visibility into other issues.
Disable JNDI lookups or disable remote codebases. This option, while effective, may involve developer work and could impact functionality.
Disconnect affected stacks. Solution stacks not connected to the organizational networks pose a dramatically lower risk from attack. Consider temporarily disconnecting the stack from networks, if possible.
Isolate the system. Create a “vulnerable network” VLAN and segment the solution stack from the rest of the enterprise network.
Last week, I saw a nice anecdote about Log4j. China’s internet regulator, the Ministry of Industry and Information Technology (MIIT), suspended a partnership with Alibaba Cloud, the cloud computing subsidiary of e-commerce giant Alibaba Group, for six months on account of the fact that it failed to promptly inform the government about a critical security vulnerability affecting the broadly used Log4j logging library.
Chinese companies are obliged to report their own software vulnerabilities to the MIIT through its National Vulnerability Database website, according to a new regulation passed this year. However, the Internet Product Security Loophole Management Regulation, which went into effect in September, only “encourages” companies to report bugs found in other’s software.
Why is the Biden administration letting Moscow set the terms of international norms for cybersecurity?
Earlier this month, the U.N. General Assembly adopted a resolution on international information security, sponsored jointly by Russia and the United States. But don’t be fooled: “Joint” sponsorship does not imply equally represented interests so much as capitulation. The resolution follows the Biden administration’s inexplicable granting of support to a summer 2021 effort in the U.N. to draft international “rules of the road” for cyberspace, a push directed primarily by Russia. Given Russia’s authoritarian control of Internet use by its citizens, incessant cyberattacks against the U.S., and penchant for manipulating international organizations, why has the Biden administration ceded so much ground to the Kremlin?
Is it true? Biden Capitulates to Russia ‘s Putin?
That question is even more perplexing in light of Biden’s repeated assertions, on the campaign trail and in office, that cybersecurity is a high priority for his administration. Despite these statements, the Kremlin’s interference in U.S. elections and its offensive cyberattacks against critical infrastructure failed to make Biden think twice about entrusting cyber norms to Russian leadership.
Biden Capitulates To Russia
The Russian government and its official media are celebrating the latest Russo–American cyber cooperation as a “historic moment.” It’s easy to understand the Kremlin’s excitement. For Russia, cyberspace is an arena in which it can challenge the U.S. in asymmetric ways that would be impossible with conventional force. Accordingly, Moscow has evolved into a major cyber power with advanced capabilities and a willingness to use them aggressively.
Given Russia’s typical disregard for international norms, this current emphasis on U.N. regulation may seem unexpected. Putin, however, is known for leveraging international institutions strategically to promote Russia’s international status as a great power and to project himself as being on an equal footing with American presidents. He also scores points at home and abroad by establishing Russia’s international leadership in cutting-edge issues such as cybersecurity.
Regulating cyberspace through multilateral institutions has been on Russia’s agenda for more than two decades. Russia proposed a set of “principles of international information security” to the U.N. as far back as 1999, though it received little support at the time. That didn’t deter Russia from refusing to sign the 2001 Budapest Convention on Cybercrime, the only legally binding cybersecurity treaty to date, because its provisions were allegedly “too intrusive.” Nonetheless, two decades after Russia began its quest to regulate the Internet, Putin’s dream came true when Russia beat out the U.S. to receive the U.N.’s approval to draft a global cybercrime treaty in 2019.
The new “joint” resolution is markedly Russian in outlook. The document entirely neglects language on “cybersecurity,” the conventional word in American discourse to describe technical attacks such as data theft, surveillance, and infrastructure hacking. Instead, it is replete with “information security,” the favored Russian military buzzword, which, in addition to its technical and defense aspects, also includes the psychological side of Russian information operations that target the decision-making processes of leaders and their people.
The precedent this move sets is worrisome. Next year, Russia and the U.S. will compete for a seat at the U.N.’s International Telecommunications Union, a highly influential body with real potential to move the dial on telecommunications and information policy for years to come. Should the Kremlin succeed again in wresting control of the ITU from America, further concessions in cyberspace should be expected.
Instead of naïvely relying on the U.N., President Biden must protect American national interests first. The Biden administration needs to push back now, and forcefully, against Russia’s cyber aggressions. The U.S. must vigorously pursue new offensive and defensive cyber-capabilities in order to bring stability to cyberspace and impose serious countermeasures on Russia for cyberattacks.
Russian President Vladimir Putin delivers a speech during an expanded meeting of the Defence Ministry Board in Moscow
Earlier this month, a high-ranking Russian foreign-ministry official, Andrey Krutskikh, who oversees the country’s international cooperation on information security, declared that World War III has already begun — in cyberspace. President Biden should stop imitating Woodrow Wilson, who believed that “idealism is going to save the world.” The unvarnished truth is that the League of Nations did not prevent World War II, and make no mistake: The U.N. will not prevent cyberwars either.
Boston-based company is in talks with banks on listing
Snyk’s backers include Tiger Global, Coatue, BlackRock
Cybersecurity startup Snyk Ltd. is making preparations for an initial public offering that could happen as early as next year, according to people familiar with the matter.
The Boston-based company is speaking to banks and aiming for listing as soon as mid-2022, said the people, who asked not to be identified because the matter is private.
The company is expected to target a market value greater than its last valuation of $8.6 billion from September, the people added.
Snyk’s plans aren’t finalized and details could still change.
A representative for Snyk declined to comment.
Snyk’s platform helps software developers integrate security into their existing workflows. Its ability to incorporate security features during the development process is designed to counter increasingly sophisticated attacks.
Snyk Chief Executive Officer Peter McKay said in an interview in March 2021 that the Boston-based company’s goal is to go public over the next couple years.
Cybersecurity has been a busy area of tech dealmaking this year. SentinelOne Inc. went public in June and has seen its stock rise close to 50% since then, while McAfee Corp. announced last month that it would be acquired for over $14 billion, including debt.
Snyk has raised over $1 billion in capital dating back to 2016, according to data provider PitchBook. Backers include Tiger Global Management, Coatue Management, BlackRock Inc., Alphabet’s GV, Salesforce Ventures, Canaan Partners and Boldstart Ventures.
A critical privilege-escalation vulnerability tracked as CVE-2021-25036 could lead to backdoors for admin access nesting in web servers.
A popular WordPress SEO-optimization plugin, called All in One SEO. This plugin has a pair of security vulnerabilities that, when combined into an exploit chain, could leave website owners open to site takeover.
What versions are vulnerable?
For both vulnerabilities, update your plugins to version 4.1.5.3 then vulnerabilities will be patched.
Privilege Escalation and SQL Injection
The more severe issue out of the two bugs is the privilege-escalation problem. It carries a critical rating of 9.9 out of 10.
The vulnerability “can be exploited by simply changing a single character of a request to upper-case,” researchers at Sucuri explained.
“When exploited, this vulnerability has the capability to overwrite certain files within the WordPress file structure. “This would allow a takeover of the website, and could elevate the privileges of subscriber accounts into admins.”
The second bug carries a high-severity CVSS score of 7.7 and affects versions 4.1.3.1 and 4.1.5.2
All in One SEO users should update to the patched version to be safe. Additonal defensive steps include:
Reviewing the administrator users in the system and removing any suspect ones;
Changing all administrator account passwords; and
Adding additional hardening to the administrator panel.
Plugin Paradise for Website Hackers
“WordPress plugins continue to be a major risk to any web application, making them a regular target for attackers.
Shadow code introduced via third-party plugins and frameworks vastly expands the attack surface for websites.”
The warning comes as new bugs continue to crop up.
Website owners need to be vigilant about third-party plugins and frameworks and stay on top of security updates. They should secure their websites using web application firewalls.
Critical Security Flaws in Garrett Metal Detectors
A number of security flaws have been uncovered in a networking component in Garrett Metal Detectors that could allow remote attackers to bypass authentication requirements, tamper with metal detector configurations, and even execute arbitrary code on the devices.
“An attacker could manipulate this module to remotely monitor statistics on the metal detector, such as whether the alarm has been triggered or how many visitors have walked through,” Cisco Talos noted in a disclosure publicized last week. “They could also make configuration changes, such as altering the sensitivity level of a device, which potentially poses a security risk to users who rely on these metal detectors.”
Talos security researcher Matt Wiseman has been credited with discovering and reporting these vulnerabilities on August 17, 2021. Patches have been released by the vendor on December 13, 2021.
The flaws reside in Garrett iC Module, which enables users to communicate to walk-through metal detectors like Garrett PD 6500i or Garrett MZ 6100 using a computer through the network, either wired or wirelessly. It allows customers to control and monitor the devices from a remote location in real-time.
The list of security vulnerabilities is below –
Successful exploitation of the aforementioned flaws in iC Module CMA version 5.0 could allow an attacker to hijack an authenticated user’s session, read, write, or delete arbitrary files on the device, and worse, lead to remote code execution.
CVE-2021-21902 (CVSS score: 7.5) – An authentication bypass vulnerability stemming from a race condition that can be triggered by sending a sequence of requests
In light of the severity of the security vulnerabilities, users are highly recommended to update to the latest version of the firmware as soon as possible.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of the cookies. Cookie & Privacy Policy
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.