

What a tangled web we weave, indeed. About 40 percent of the world’s population uses the Web for news, entertainment, communication and myriad other purposes [source: Internet World Stats]. Yet even as more and more people log on, they are actually finding less of the data that’s stored online. That’s because only a sliver of what we know as the World Wide Web is easily accessible.
The so-called surface Web, which all of us use routinely, consists of data that search engines can find and then offer up in response to your queries. But in the same way that only the tip of an iceberg is visible to observers, a traditional search engine sees only a small amount of the information that’s available — a measly 0.03 percent [source: OEDB].
As for the rest of it? Well, a lot of it’s buried in what’s called the deep Web. The deep Web (also known as the undernet, invisible Web and hidden Web, among other monikers) consists of data that you won’t locate with a simple Google search.
No one really knows how big the deep Web really is, but it’s hundreds (or perhaps even thousands) of times bigger that the surface Web. This data isn’t necessarily hidden on purpose. It’s just hard for current search engine technology to find and make sense of it.
There’s a flip side of the deep Web that’s a lot murkier — and, sometimes, darker — which is why it’s also known as the dark web. In the dark Web, users really do intentionally bury data. Often, these parts of the Web are accessible only if you use special browser software that helps to peel away the onion-like layers of the dark Web.
This software maintains the privacy of both the source and the destination of data and the people who access it. For political dissidents and criminals alike, this kind of anonymity shows the immense power of the dark Web, enabling transfers of information, goods and services, legally or illegally, to the chagrin of the powers-that-be all over the world.
Just as a search engine is simply scratching the surface of the Web, we’re only getting started. Keep reading to find out how tangled our Web really becomes.
Hidden in Plain Site
The deep Web is enormous in comparison to the surface Web. Today’s Web has more than 555 million registered domains. Each of those domains can have dozens, hundreds or even thousands of sub-pages, many of which aren’t cataloged, and thus fall into the category of deep Web.
Although nobody really knows for sure, the deep Web may be 400 to 500 times bigger that the surface Web [source: BrightPlanet]. And both the surface and deep Web grow bigger and bigger every day.
To understand why so much information is out of sight of search engines, it helps to have a bit of background on searching technologies.
Search engines generally create an index of data by finding information that’s stored on Web sites and other online resources. This process means using automated spiders or crawlers, which locate domains and then follow hyperlinks to other domains, like an arachnid following the silky tendrils of a web, in a sense creating a sprawling map of the Web.
This index or map is your key to finding specific data that’s relevant to your needs. Each time you enter a keyword search, results appear almost instantly thanks to that index. Without it, the search engine would literally have to start searching billions of pages from scratch every time someone wanted information, a process that would be both unwieldy and exasperating.
But search engines can’t see data stored to the deep Web. There are data incompatibilities and technical hurdles that complicate indexing efforts. There are private Web sites that require login passwords before you can access the contents. Crawlers can’t penetrate data that requires keyword searches on a single, specific Web site. There are timed-access sites that no longer allow public views once a certain time limit has passed.
All of those challenges, and a whole lot of others, make data much harder for search engines to find and index. Keep reading to see more about what separates the surface and deep Web.
Just Below the Surface

If you think of the Web like an iceberg, the huge section below water is the deep Web, and the smaller section you can see above the water is the surface Web.
As we’ve already noted, there are millions upon millions of sub-pages strewn throughout millions of domains. There are internal pages with no external links, such as internal.howstuffworks.com, which are used for site maintenance purposes. There are unpublished or unlisted blog posts, picture galleries, file directories, and untold amounts of content that search engines just can’t see.
Here’s just one example. There are many independent newspaper Web sites online, and sometimes, search engines index a few of the articles on those sites. That’s particularly true for major news stories that receive a lot of media attention. A quick Google search will undoubtedly unveil many dozens of articles on, for example, World Cup soccer teams.
But if you’re looking for a more obscure story, you may have to go directly to a specific newspaper site and then browse or search content to find what you’re looking for. This is especially true as a news story ages. The older the story, the more likely it’s stored only on the newspaper’s archive, which isn’t visible on the surface Web. Subsequently, that story may not appear readily in search engines — so it counts as part of the deep Web.
Deep Potential

If we can unlock the deep Web to search professional databases and difficult-to-access deep information, fields such as medicine would immediately benefit.
Data in the Deep Web is hard for search engines to see, but unseen doesn’t equal unimportant. As you can see just from our newspaper example, there’s immense value in the information tucked away in the deep Web.
The deep Web is an endless repository for a mind-reeling amount of information. There are engineering databases, financial information of all kinds, medical papers, pictures, illustrations … the list goes on, basically, forever.
And the deep Web is only getting deeper and more complicated. For search engines to increase their usefulness, their programmers must figure out how to dive into the deep Web and bring data to the surface. Somehow they must not only find valid information, but they must find a way to present it without overwhelming the end users.
As with all things business, the search engines are dealing with weightier concerns than whether you and I are able to find the best apple crisp recipe in the world. They want to help corporate powers find and use the deep Web in novel and valuable ways.
For example, construction engineers could potentially search research papers at multiple universities in order to find the latest and greatest in bridge-building materials. Doctors could swiftly locate the latest research on a specific disease.
The potential is unlimited. The technical challenges are daunting. That’s the draw of the deep Web. Yet there’s a murkier side to the deep Web, too — one that’s troubling to a lot of people for a lot reasons.
Darkness Falls
The deep Web may be a shadowland of untapped potential, but with a bit of skill and some luck, you can illuminate a lot of valuable information that many people worked to archive. On the dark Web, where people purposely hide information, they’d prefer it if you left the lights off.
The dark Web is a bit like the Web’s id. It’s private. It’s anonymous. It’s powerful. It unleashes human nature in all its forms, both good and bad.
The bad stuff, as always, gets most of the headlines. You can find illegal goods and activities of all kinds through the dark Web. That includes illicit drugs, child pornography, stolen credit card numbers, human trafficking, weapons, exotic animals, copyrighted media and anything else you can think of. Theoretically, you could even, say, hire a hit man to kill someone you don’t like.
But you won’t find this information with a Google search. These kinds of Web sites require you to use special software, such as The Onion Router, more commonly known as Tor.
Tor is software that installs into your browser and sets up the specific connections you need to access dark Web sites. Critically, Tor is an encrypted technology that helps people maintain anonymity online. It does this in part by routing connections through servers around the world, making them much harder to track.
Tor also lets people access so-called hidden services — underground Web sites for which the dark Web is notorious. Instead of seeing domains that end in .com or .org, these hidden sites end in .onion. On the next page we’ll peel back the layers of some of those onions.
Titillating Tor
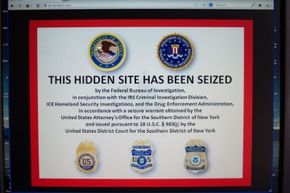
In October 2013, U.S. authorities shut down Silk after the alleged owner of the site Ross William Ulbricht was arrested.
The most infamous of these onion sites was the now-defunct Silk Road, an online marketplace where users could buy drugs, guns and all sorts of other illegal items. The FBI eventually captured Ross Ulbricht, who operated Silk Road, but copycat sites like Black Market Reloaded are still readily available.
Oddly enough, Tor is the result of research done by the U.S. Naval Research Laboratory, which created Tor for political dissidents and whistleblowers, allowing them to communicate without fear of reprisal.
Tor was so effective in providing anonymity for these groups that it didn’t take long for the criminally-minded to start using it as well.
That leaves U.S. law enforcement in the ironic position of attempting to track criminals who are using government-sponsored software to hide their trails. Tor, it would seem, is a double-edged sword.
Anonymity is part and parcel on the dark Web, but you may wonder how any money-related transactions can happen when sellers and buyers can’t identify each other. That’s where Bitcoin comes in.
If you haven’t heard of Bitcoin, it’s basically an encrypted digital currency. Like regular cash, Bitcoin is good for transactions of all kinds, and notably, it also allows for anonymity; no one can trace a purchase, illegal or otherwise.
Bitcoin may be the currency of the future — a decentralized and unregulated type of money free of the reins of any one government. But because Bitcoin isn’t backed by any government, its value fluctuates, often wildly. It’s anything but a safe place to store your life savings. But when paired properly with Tor, it’s perhaps the closest thing to a foolproof way to buy and sell on the Web.
The Brighter Side of Darkness

The dark Web is home to alternate search engines, e-mail services, file storage, file sharing, social media, chat sites, news outlets and whistleblowing sites, as well as sites that provide a safer meeting ground for political dissidents and anyone else who may find themselves on the fringes of society.
The dark Web has its ominous overtones. But not everything on the dark side is bad. There are all sorts of services that don’t necessarily run afoul of the law.
In an age where NSA-type surveillance is omnipresent and privacy seems like a thing of the past, the dark Web offers some relief to people who prize their anonymity. Dark Web search engines may not offer up personalized search results, but they don’t track your online behavior or offer up an endless stream of advertisements, either. Bitcoin may not be entirely stable, but it offers privacy, which is something your credit card company most certainly does not.
For citizens living in countries with violent or oppressive leaders, the dark Web offers a more secure way to communicate with like-minded individuals. Unlike Facebook or Twitter, which are easy for determined authorities to monitor, the dark Web provides deeper cover and a degree of safety for those who would badmouth or plot to undermine politicians or corporate overlords.
A paper written by researchers at the University of Luxembourg attempted to rank the most commonly accessed materials on the dark Web. What they found was that although sites trading in illegal activities and adult content are very popular, so too are those concerned with human rights and freedom of information [Source: ArXiv].
So although the dark Web definitely has its ugly side, it has great potential, too.
Even Deeper
The deep Web is only getting deeper. Its store of human knowledge and trivialities grows more massive every day, complicating our efforts to make sense of it all. In the end, that’s perhaps the biggest challenge behind the Internet that we’ve created.
Programmers will continue to improve search engine algorithms, making them better at delving into deeper layers of the Web. In doing so, they’ll help researchers and businesses connect and cross-reference information in ways that were never possible before.
At the same time, the primary job of a smart search engine is not to simply find information. What you really want it to do is find the most relevant information. Otherwise, you’re left awash in a sea of cluttered data that leaves you wishing you had never clicked on that search button.
That’s the problem of so-called big data. Big data is the name for sets of data that are so large that they become unmanageable and incoherent. Because the Internet is growing so quickly, our whole world is overrun with data, and it’s hard for anyone to make sense of it all — even all of those powerful, all-knowing computers at Bing and Google headquarters.
As the Internet grows, every large company spends more and more money on data management and analysis, both to keep their own organizations functioning and also to obtain competitive advantages over others. Mining and organizing the deep Web is a vital part of those strategies. Those companies that learn to leverage this data for their own uses will survive and perhaps change the world with new technologies. Those that rely only on the surface Web won’t be able to compete.
In the meantime, the deep Web will continue to perplex and fascinate everyone who uses the Internet. It contains an enthralling amount of knowledge that could help us evolve technologically and as a species when connected to other bits of information. And of course, its darker side will always be lurking, too, just as it always does in human nature. The deep Web speaks to the fathomless, scattered potential of not only the Internet, but the human race, too.
Lots More Information
Author’s Note: How the Deep Web Works
The Deep Web is a vague, ambiguous place. But while researching this story, it was easy to conclude at least one thing for sure — most news headlines tend to sensationalize the dark Web and its seedier side, and rarely mention the untapped potential of the deep Web. Articles about illegal drugs and weapons obviously draw more readers than those detailing the technical challenges of harvesting data from the deep Web. Read the negative, breathless articles with a grain of salt. It’s worth remembering that there’s a whole lot more to the deep Web than the obvious criminal element. As engineers find better, faster ways to catalog the Web’s stores of data, the Internet as a whole could transform our society in amazing ways.
You may also enjoy reading, CVEs You May Have Missed While Log4J Stole The Headlines
Stay informed of the latest Cybersecurity trends, threats and developments. Sign up for RiSec Weekly Cybersecurity Newsletter Today
Remember, CyberSecurity Starts With You!
- Globally, 30,000 websites are hacked daily.
- 64% of companies worldwide have experienced at least one form of a cyber attack.
- There were 20M breached records in March 2021.
- In 2020, ransomware cases grew by 150%.
- Email is responsible for around 94% of all malware.
- Every 39 seconds, there is a new attack somewhere on the web.
- An average of around 24,000 malicious mobile apps are blocked daily on the internet.



